
Basic Information
Authors: Xinchi Qiu, Javier Fernandez-Marques, Pedro P. B. Gusmao, Yan Gao, Titouan Parcollet and Nicholas D. Lane
Organization: University of Cambridge, University of Oxford,
Source: ICLR 2022
Source Code: None
Cite: Qiu, Xinchi, et al. “ZeroFL: Efficient on-device training for federated learning with local sparsity.” International Conference on Learning Representations (ICLR). 2022.
Content
Motivation
The use of sparse operations (e.g. convolutions) at training time has recently been shown to be an effective technique to accelerate training in centralised settings. The resulting models are as good or close to their densely-trained counterparts despite reducing by up to 90% their FLOPs budget and, resulting in an overall up to 3.3× training speedup. However, it is unclear how the different FL-specific challenges (i.e. data imbalance, stateless clients, periodic aggregation) will restrict the quality of the global model.
Evaluation
Metric: Accuracy
Datasets
FEMNIST, CIFAR10, Speecg Commands dataset.
Result
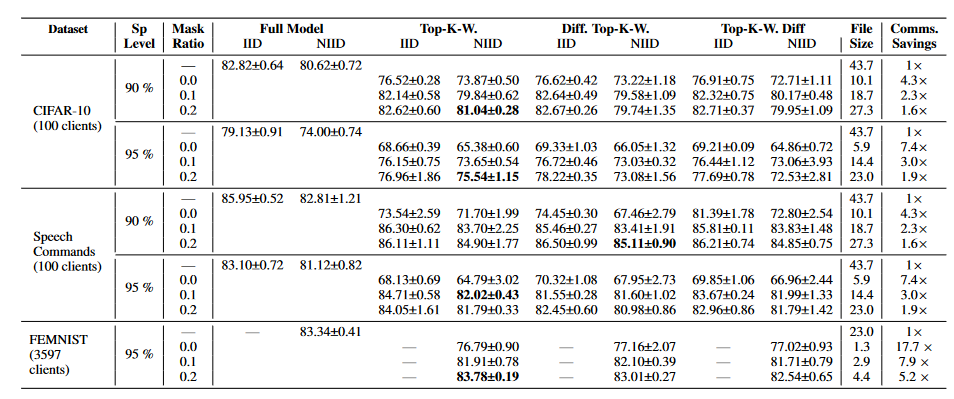
Table 1. Results with ZeroFL on CIFAR10 and SpeechCommands for both IID ($\alpha$=1.0) and non-IID ($\alpha$=1000) settings. We report the test accuracy at 700, 200 and 1K communication rounds respectively for CIFAR10, Speech Commands and FEMNIST. We report the size (in MB) of the artifact to be transmitted to the server for aggregation, which has been compressed following the CSR sparse format representation. ZeroFL improves the performance while reducing the uplink communication cost up to a factor of 7.4× compared to vanilla SWAT. For each sparsity level and dataset, we highlight in bold the best masking strategy. For clarity we do this on the non-IID results only. More results can be found in Appendix.
Method
SWAT
The SWAT framework embodies two strategies in the training process. During each forward pass, the weights are partitioned into active weights and non-active weights by a top-K (in magnitude) operator and only the active weights are used.
Then in the backward pass, the retained layer inputs $a_{l-1}$ are also partitioned into active and nonactive by using the same top-K procedure. It is worth noticing that even weights and activations and sparsified in the forward and backward pass, the gradients generated through the training process are dense. Therefore, the resulting model is a dense.
However, in a typical cross-device scenario, client’s availability is low and new data points are continuously being presented to the system as new clients participate in training rounds. This means that clients are likely to participate only once. Such training behaviour inevitably leads to distributions of weights that change over time, making the application of sparsity inducing methods more difficult as a result.
ZeroFL: local sparsification of uplink communication
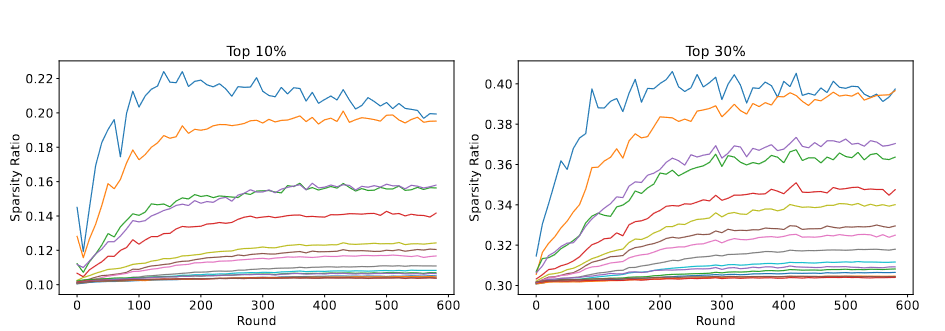
Figure 1. Evolution of the non-zero weights ratio after server aggregation (i.e. number of weights that are non-zero divided by the total number of parameter in that layer) of all CNN layers of a ResNet-18 trained on CIFAR10 with FL. Each of the 100 clients either send the top-10% or top-30% (i.e. weights with the highest norm) to the server.
Figure 2 shows: First, a significant overlap exists between clients across all CNN layers. Indeed, the non-zero ratio almost never exceeds 0.40, meaning that at least 60% of the weights are not comprised in the top-K weights of the clients. This advocates for the fact that the most important weights for the current task tend to be the same across clients. Then, we can see that the non-zero ratio does not seem to be significantly impacted by changing K from 10% to 30% as it only slightly increases for most CNN layers. This is explained by the fact that while clients may have different top-10% weights, they tend to have the same top-30% parameters: a specific non-zero weight that is reported as a top-10% element from a single client out of the selected ones is most likely to be reported as non-zero as well by more of them when we increase to top-30%.** In short, top-30% will gather most of information about weights** that are considered as being important for the task while keeping the same level of sparsity.
Motivated by our previous analysis which suggests that not all weights are necessary to be transferred to the central server for aggregation, we propose ZeroFL: a method that applies local sparsification before uplink communication. More precisely, we provide three strategies for local sparsification to improve the performance of sparse training while reducing the communication cost at the same time.
Top-K-Weights. Only top-K active weights are involved in the validation and inference stages, and an important part of these weights tend not to change during training. Therefore, the first local sparsification method is to sparsify the top-K weights on the client-side before sending them back to the central server for aggregation.

Comments
Pros
Cons
- overlapping weights are not solid proved. 30% is not reasonable.
- experiments are not sufficient, no baseline including
- no open-source code.
- An obvious mistake. Author said As $\alpha \rightarrow \infty$, partitions become more uniform (IID), and as $\alpha \rightarrow 0$, partitions tend to be more heterogeneous. But author choose $\alpha = 1$ for IID and $\alpha = 1000$ for non-IID.
Further work
(need further experiment)
Comments
(need further experiment)




