
Basic Information
Authors: Zhipeng Luo, Gongjie Zhang, Changqing Zhou, Tianrui Liu, Shijian Lu, Liang Pan
Organization: Nanyang Technological University
Source: WACV 2023
Source Code: None
Cite: Luo, Zhipeng, et al. “TransPillars: Coarse-to-Fine Aggregation for Multi-Frame 3D Object Detection.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.
Content
Motivation
Leveraging multiple frames of point clouds, on the other hand, provides critical temporal cues that mitigate the above-mentioned challenges [38, 24, 41]. The lower section of Fig. 1 illustrates that points accumulated from consecutive frames progressively form a holistic depiction of the object. Nevertheless, leveraging temporal information is not trivial. A straightforward approach is simply concatenating points from multiple frames. However, such a method does not explicitly model cross-frame relations and the performance deteriorates for moving objects as the number of concatenated frames exceeds a certain threshold.
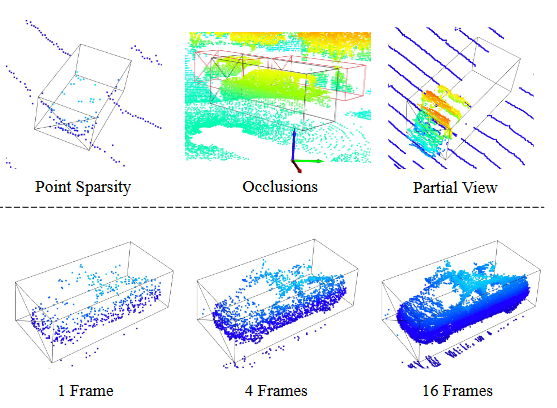
Figure 1. Upper: Illustration of challenges in point cloud object detection. Occluded objects are indicated by red boxes and LiDAR is highlighted by the axes. Lower: Sequential frames contain complementary information and aggregating the complementary information leads to a more complete view.
Some recent approaches resort to fusing multi-frame information via feature aggregation. In particular, inspired by relational networks proposes a 3D multi-frame attention network that performs feature alignment and aggregation on pooled instance-level features.
he RoI pooling process inevitably leads to 1) loss of instance details due to the misalignment between RoI and the object as dimension and location estimation is imperfect, 2) loss of contextual information due to separation of the objects from the scene, both undermining cross-frame correlation modeling.
Moreover, such a method depends on high-quality region proposals, which are not guaranteed under the above challenges associated with point clouds.
Motivated by the above observations, in this paper, we explore aggregating multi-frame information directly from feature maps. Specifically, we propose TransPillars, which builds on top of PointPillars and employs the attention mechanism of transformer to perform cross-frame feature aggregation at voxel-level. To avoid prohibitive computational complexity and memory consumption, instead of performing global attention computations between each pair of tokens from the feature maps as in regular transformers, we adopt deformable attention for feature aggregation that each voxel adaptively attends to a small number of target voxels. To address the limitations of the original deformable attention in the cross-frame matching process, we develop a variant of deformable attention by incorporating the query-key matching operation in the attention module to better adapt to moving objects. In order to effectively capture the motion of fast-moving objects, we introduce a novel coarse-to-fine aggregation strategy to first identify the highlevel instance correspondences to guide the subsequent fusion of fine features for accurate localization.
Evaluation
Metric: mAP (IoU=0.7), mAPH (IoU=0.7)
Datasets
nuScenes, Waymo
Result

Table 1. Performance comparison with multi-frame 3D detectors on the nuScenes dataset. T.C., Moto. and Cons. stand for traffic cone, motorcycle, and construction vehicle, respectively. Mean Average Precision (mAP) is used for evaluation.
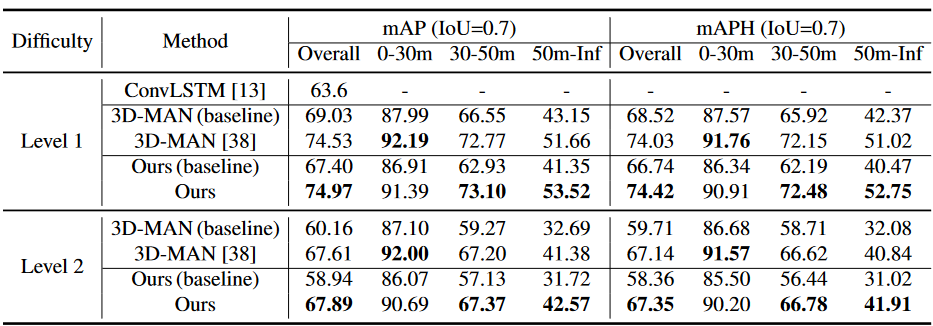
Table 2. Performance comparison with multi-frame 3D detectors on the Waymo validation dataset. Even with a less competitive baseline model, our method outperforms the state-of-the-art multi-frame detector 3D-MAN.
Method
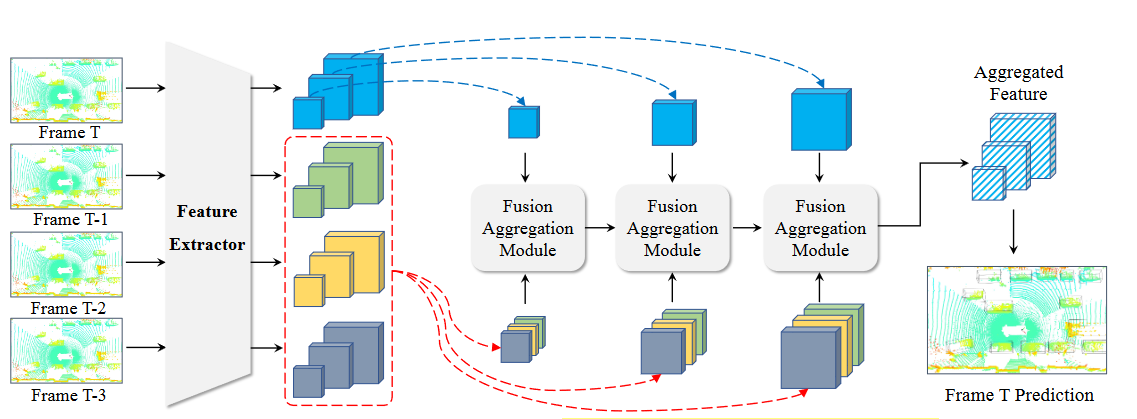
Figure 2. The framework of the proposed TransPillars: Given multiple consecutive point cloud frames as inputs, multi-scale features are first extracted by a feature extractor which are then aggregated with multiple Fusion Aggregation Modules in a coarse-to-fine manner. We first aggregate coarse features to extract high-level cross-frame correspondences and then employ them to guide the aggregation of fine features. Finally, the multi-scale aggregated features are fused to produce the final predictions. Best viewed in color.
Analysis Framework
todo
Convergence Analysis
Assumption 1:(L-Smoothness) \(||\nabla F_i(x) - \nabla F_i(y)|| \le L||x-y||\)
Assumption 2:(Unbiased Gradient and Bounded Variance) \(\mathbb{E}_\xi[||g_i(x|\xi)\nabla F_i(x)||^2] \le \sigma^2 L||x-y||\)
Assumption 3:(Bounded Dissimilarity) \(\exists \beta^2\ge 0, \kappa^2\ge 0 s.t. \sum_{i=1}^{m}w_i||\nabla F_i(x)||^2 \le \beta^2||\sum_{i=1}^{m}w_i\nabla F_i(x)||^2 + \kappa^2\)
Base above assumptions, author gets following theorem:
Theorem 1(Convergence to \(\widetilde{F}(x)\) Stationary Point). Under assumptions 1 to 3, any fedrated optimizaition algorithm that follows the update rule \eqref{4}, will converge to a stationary point. if learning rate \(\eta = \sqrt{\frac{m}{\hat{\tau}T}}\), then the optimization error will be bounded as follows: \(\min_{t\in[T]} \mathbb{E}|| \nabla \widetilde{F}(x^{(t,0)})||^2 \le O(\frac{\hat{\tau}\eta}{m\tau_{eff}}) + O(\frac{A\eta\sigma^2}{m}) + O(B\eta^2\sigma^2) + O(C\eta^2\kappa^2) \tag6\) TODO
Comments
Pros
- Solve the heterogeneity in the Number of Local Updates in Federated Learning
- Proposed a general framework which can guarantee the convergence to the stationary point.
Cons
(need further experiment)
Further work
Extending the theoretical framework to adaptive optimization methods or gossip-based training method.
Comments
(need further experiment)




