
Basic Information
Authors: Junyuan Hong, Haotao Wang, Zhangyang Wang and Jiayu Zhou
Organization: Michigan State University, The University of Texas at Austin
Source: ICLR 2022
Source Code: https://github.com/illidanlab/SplitMix
Cite: Hong, Junyuan, et al. “Efficient split-mix federated learning for on-demand and in-situ customization.” arXiv preprint arXiv:2203.09747 (2022).
Content
Motivation
When deploying federated learning, one challenge in real-world applications is the run-time (i.e., test-time) dynamics. One common and specific type of dynamics is resource dynamics: For each application, the allocated on-device resources (e.g., run-time memory, CPU bandwidth, etc.) may vary drastically during run-time, depending on how the resource allocation of the running programs are prioritized on a participant’s device (Xu et al., 2021). Another type of dynamics is the robustness dynamics: The constantly changing outside environment can make different requirements on the safety (or robustness) level of the model (Wang et al., 2020). For instance, the quality of real-time videos captured by autonomous cars can suddenly degrade, e.g., on entering a poor-lighted alley or tunnel from a well-lighted avenue, on entering a section of bumpy road which leads to a sudden burst of blurring in the videos, etc. However, as illustrated in Figure 1a, we show that conventional static-model FL methods, represented FedAvg, cannot provide such customization.
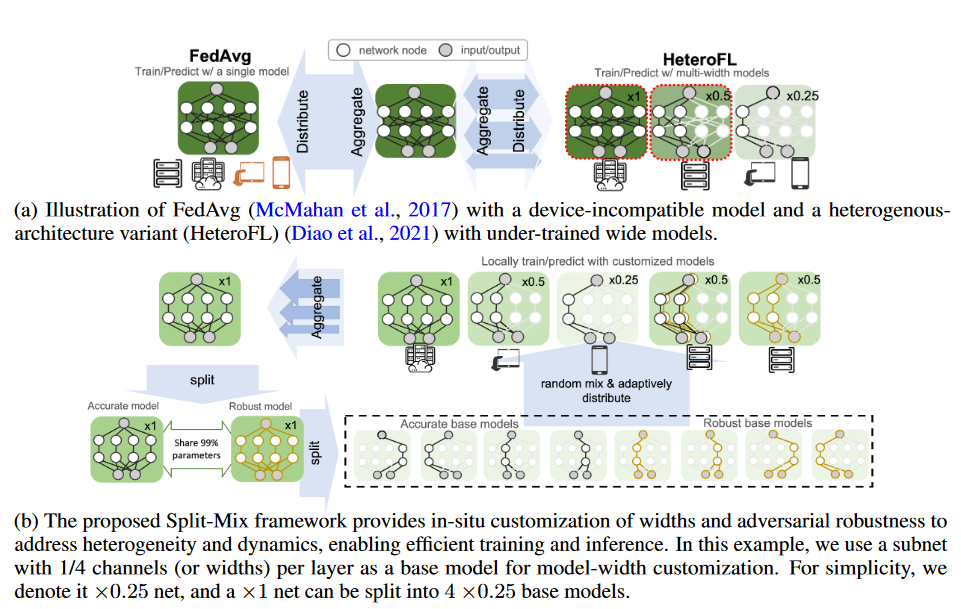
Figure 1. Comparison of traditional and proposed methods.
Moreover, HeteroFL suffers from under-training in its large models due to local budget constraints as shown in Figure 1a. The degradation could be worsened as facing data heterogeneity: The training datasets from participants are not independent and identically distributed (non-i.i.d.). When one device with a unique data distribution cannot afford training a large model, the global large model may not transfer to the unseen distribution.
To address the aforementioned challenges from heterogeneity and dynamics, we study a novel SplitMix approach to enable FL on heterogeneous devices and achieve in-situ model customization for resource efficiency and robustness: The size and robustness of the resultant model can be efficiently customized at run-time. Specifically, we first split the complete knowledge in a large model into several small base sub-networks (shards) according to model widths and robustness levels. To complete the knowledge, we let the base models be fully trained on all clients. To provide customized models, we mix selected base models to construct the desired model size and robustness. We illustrate the main idea in Fig. 1b.
Evaluation
Metric: Accuracy, MACs
Baselines: FedAVG(small), Split-Mix
Datasets
CIFAR10, Digits, DomainNet
Result
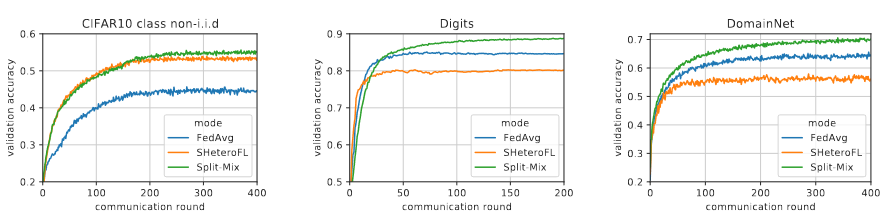
Figure 2. Validation accuracy of budget-compatible full-wdith nets by iterations.
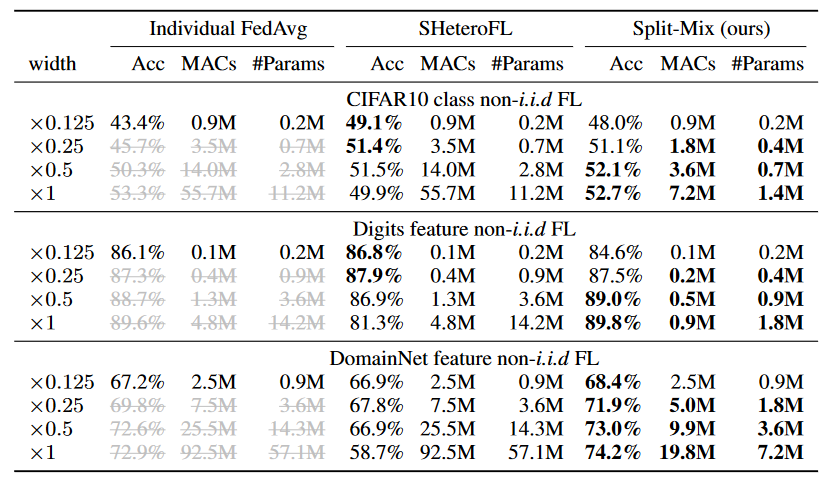
Table 1. Test results of customizing model width. MACs and the number of parameters are counted at inference time. Grey texts indicate that the training cannot conform the predefined budget constraint. The ‘M’ after metric values means $\times 10^6$.
Figure 3. Client-wise statistics of test accuracy, training and communication efficiency by budget constraints. The MACs quantify the complexity of one batch optimization in a client, and the number of parameters per round round are the ones uploaded to (or downloaded from) a server. Test accuracy is by the full-width networks. The results of FedAvg are from budget-compatible $\times 0.125$ nets.
Method
More accessible data by splitting wide networks.
Since a wide network cannot fit into budget insufficient clients, we split it into budget-compatible sub-networks by channels (width) while maintaining the the total width. In terms of memory limitations, each sub-network can be painlessly and individually trained in all clients.
We select different sets of base models for a budget-limited client per round, which is inspired by FedEnsemble (Shi et al., 2021) and is presented in Algorithm 2. Hence, all base models can be ever trained on the client for multiple communication rounds, though not continuously every round.
Boost accuracy by mixture of subnet experts.
To craft a wide model, we combine the outputs of multiple ×r base models until the size of the ensemble reaches the same as the number of channels, e.g., [R/r] bases for an ×R net.


Comments
Pros
1.Considering data non-iid
Cons
- All base models need to be trained, which may slow down the convergence. If one client can only train one base model, due to resource constraint, the convergence is slow.
- It based on random search instead of a good search space.
- I doubt whether it can converge as fast as he declare.
Further work
Extending the theoretical framework to adaptive optimization methods or gossip-based training method.
Comments
(need further experiment)




