
Basic Information
Authors: Colton Stearns, Davis Rempe, Jie Li, Rares Ambrus, Sergey Zakharov, Vitor Guizilini, Yanchao Yang, and Leonidas J. Guibas
Organization: Stanford University, Toyota Research Institute
Source: Advances in Neural Information Processing Systems 2020
Source Code: https://github.com/coltonstearns/SpOT
Cite: Stearns, Colton, et al. “SpOT: Spatiotemporal Modeling for 3D Object Tracking.” Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII. Cham: Springer Nature Switzerland, 2022.
Content
Motivation
A distinct challenge faced by 3D multi-object tracking is that of data association when using LIDAR data as the main source of observation, due to the sparse and irregular scanning patterns inherent in time-of-flight sensors designed for outdoor use.
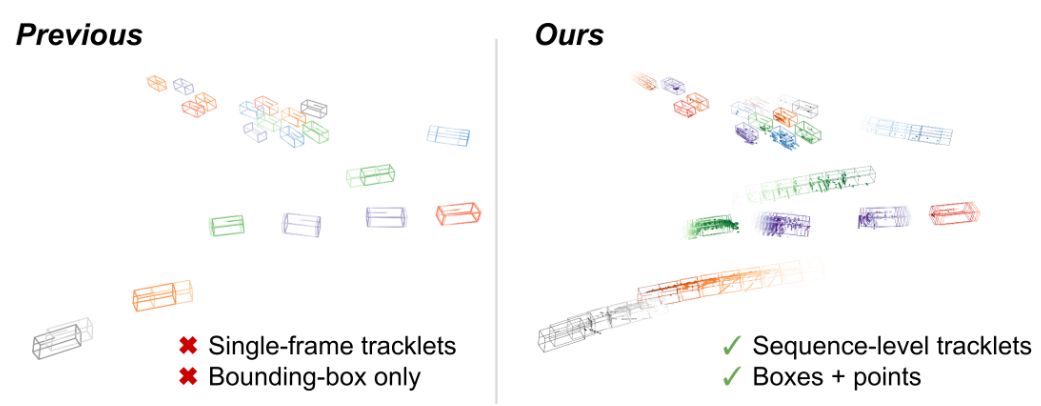
Figure 1. Previous works use a highly abstracted tracklet representation (eg. bounding boxes) and a compressed motion model (Kalman filter or constant velocity). We efficiently maintain an active history of object-level point clouds and bounding boxes for each tracklet.
Single-frame detection results are modeled as bounding boxes or center-points and compared to the same representation of the tracked objects from the last visible frame. Although it touts simplicity, this strategy does not fully leverage the spatiotemporal nature of the 3D tracking problem: temporal context is often over-compressed into a simplified motion model such as a Kalman filter or a constant-velocity assumption. Moreover, these approaches largely ignore the low-level information from sensor data in favor of abstracted detection entities, making them vulnerable to crowded scenes and occlusions.
However, improving spatiotemporal context by integrating scene-level LIDAR data over time is challenging due to the large quantity of sampled points along with sparse and irregular scanning patterns.
In this work, we propose a spatiotemporal representation for object tracklets (see Fig. 1). Our method, SpOT (Spatiotemporal Object Tracking), actively maintains the history of both object-level point clouds and bounding boxes for each tracked object. At each frame, new object detections are associated with these maintained past sequences; the sequences are then updated using a novel 4D backbone to refine the entire sequence of bounding boxes and to predict the current velocity, both of which are used to forecast the object into the next frame.
Evaluation
Metric: tracking performance
Datasets
nuScenes and Waymo
Result
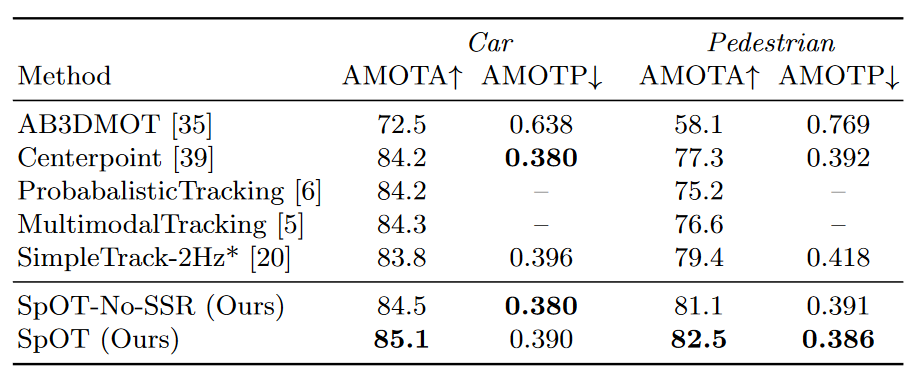
Table 1. Tracking performance on the nuScenes dataset validation split. An asterisk* denotes a preprint.
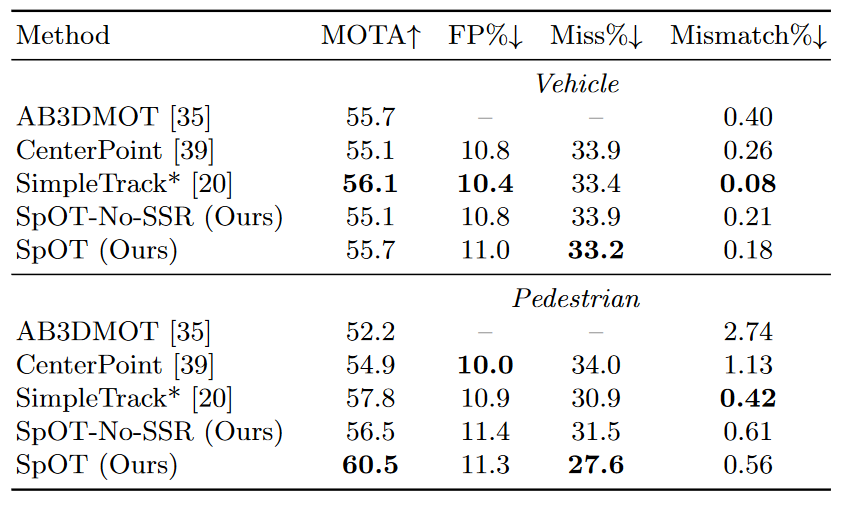
Table 1. Tracking performance on the Waymo Open dataset validation split. An asterisk* denotes a preprint.
Method
In this work, we address the problem of 3D multi-object tracking (MOT) from LIDAR sensor input. The goal of this task is to uniquely and consistently identify every object in the scene in the form of tracklets $O_t = \lbrace T_t \rbrace$ at each frame of input t. As input, the current LIDAR point cloud $P_t$ is given along with detection results $D_t = \lbrace b_t \rbrace$, in the form of 7-DoF amodal bounding boxes $b_i = (x, y, z, l, w, h, \theta)_i$ and confidence $s_i$, from a given detector. In contrast to previous works that maintain only single-frame tracklets, we model our tracklet as $T_t = \lbrace S_t, Q_t \rbrace$ to include both a low-level history of object points $Q_t$ and the corresponding sequence of detections $S_t$. In each tracklet, $_St$ includes the estimated state trajectory of the tracked object within a history window:
\[S_t = \lbrace s_i = (b, v_x, v_y, c, s)_i \rbrace, \quad t-K \le i \le t\]where $K$ is a pre-defined length of maximum history. Tracklet state has 11 elements and includes a 7-DoF bounding box $b$, a birds-eye-view velocity $(v_x, v_y)$, an object class c, and a confidence score $s$.
$Q_t$ encodes the spatiotemporal information from raw sensor observations in the form of time-stamped points:
\[Q_t = \lbrace \hat P_i = (x,y,z,i) \rbrace, \quad t-K \le i \le t\]where $\hat P_i$ is the cropped point cloud region from $P_i$ according to the associated detected bounding box $b_i$ at time $i$. We enlarge the cropping region by a factor of 1.25 to ensure that $\hat P_i$ is robust through imperfect detection results.
As depicted in Fig. 2, we propose a tracking framework that follows the tracking-by-detection paradigm while leveraging low-level sensory information. At each timestep t, we first predict the current tracklets $\hat T_t$ based on the stored previous ones $T_{t-1}$:
\[\hat T_t = Predict(T_{t-1}) = \lbrace \hat S_t, Q_{t-1} \rbrace\] \[\hat S_t = \lbrace \hat s_i = (x+v_x, y+v_y,z,l,w,h,\theta,v_x, v_y, c, s)_{i-1} \rbrace, \quad t-K \le i \le t\]
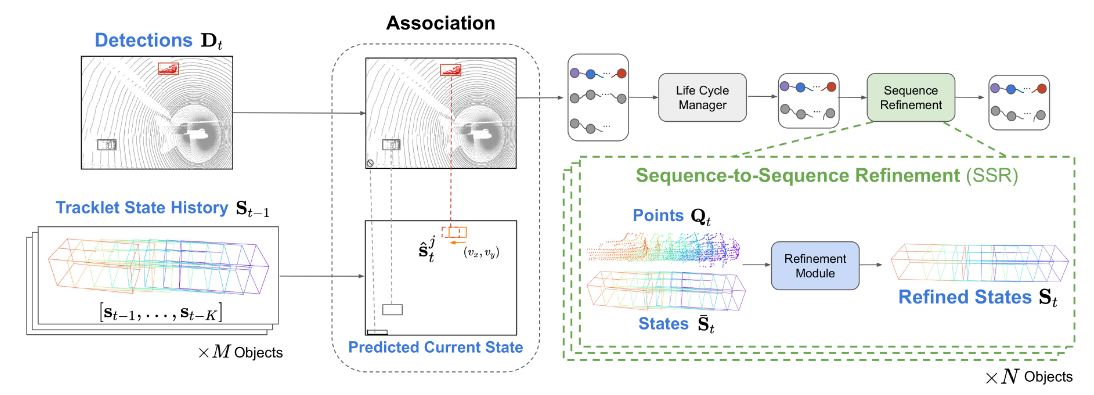
Figure 2. Tracking algorithm overview. SpOT maintains sequence-level tracklets containing both object bounding box states and object point clouds from the last K timesteps. At each step, tracklets are associated to current detections using the predicted current state, and then the updated tracklets are refined by the learned SSR module to improve spatiotemporal consistency.
We compare the last state of the predicted tracklets $\hat s_t$ to off-the-shelf detection results $D_t$ to arrive at associated tracklets:
\[\bar T_t = Association(\hat S_t, D_t, P_t) = \lbrace \bar S_t, Q_t \rbrace\]where $\bar S_t$ is the previous state history $S_{t−1}$ concatenated with its associated detection and Qt is the updated spatiotemporal history. Finally, we conduct the posterior tracklet update using a novel sequence-to-sequence refinement (SSR) module:
\[S_t = SSR(\bar S_t, Q_t)\]Sequence-to-Sequence Refinement (SSR) Module
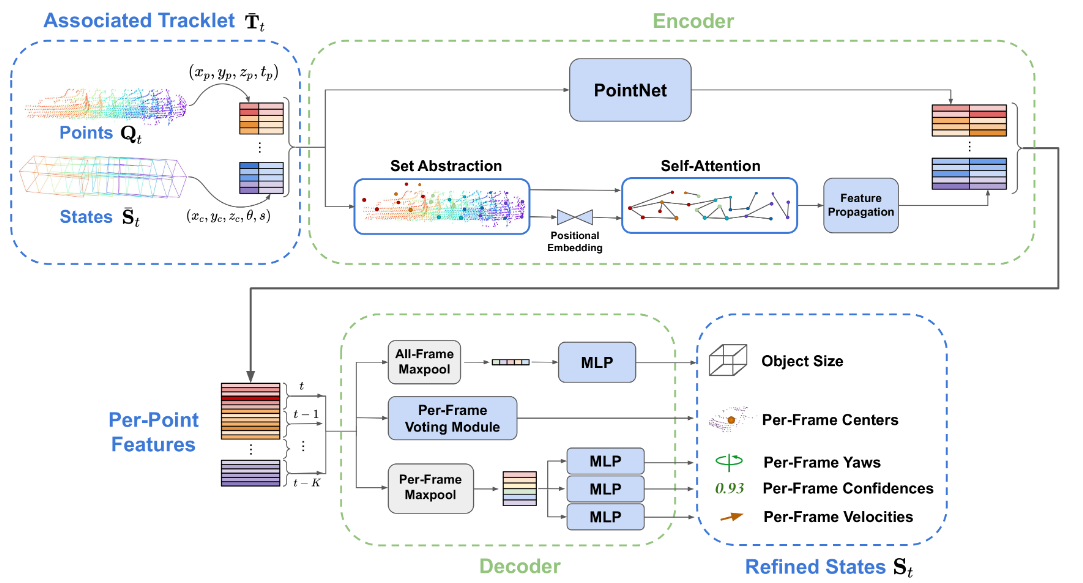
Figure 3. Architecture of the sequence-to-sequence refinement (SSR) network. Given a tracklet containing object points and bounding boxes after association to a detection, the encoder first extracts spatiotemporal features corresponding to each input point. The features are given to the decoder which predicts a refined state trajectory and velocities to be used for subsequent association.
Comments
Pros
- very clearly
- good paper that tackles the tracking problem
Cons
- late fusion may cause ill pose. Although refinement may mitigate this problem, but it will bring more cost.
Further work
None
Comments
(need further experiment)




