
Basic Information
Authors: Yimin Wei, Hao Liu, Tingting Xie, Qiuhong Ke, Yulan Guo
Organization: 1Sun Yat-sen University, Shenzhen Campus of Sun Yat-sen University
Source: WACV 2022
Source Code: None
Cite: Wei, Yimin, et al. “Spatial-temporal transformer for 3d point cloud sequences.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022.
Content
Motivation
4D semantic segmentation is challenging due to several reasons. First, different from regular and dense 2D image sequences, raw point cloud sequences usually have a regular order in the temporal domain but are unordered in the spatial domain. Besides, point clouds are usually highly sparse. Therefore, it is extremely difficult to model the spatiotemporal structure in a point cloud sequence. Second, it is hard to predict the motion of points within a point cloud sequence. However, the construction of spatio-temporal neighborhoods rely on tracking the motion of points across different frames. It is therefore, difficult to effectively extract and aggregate the spatio-temporal context information of points within inter-frame neighborhoods.
Although existing point-based methods can avoid the quantization error by directly processing raw point cloud sequences, they still face two major challenges. First, existing methods usually adopt attention operations or Recurrent Neural Network (RNN) models [15, 8] to fuse inter-frame features. However, since these methods reply on long-term dependency, the inter-frame information fusion conducted at a frame depends on the fusion of the information of all its previous frames, leading to information redundancy. It is necessary for an inter-frame feature fusion strategy to capture spatio-temporal point context information while reducing the redundancy of previous frames. Besides, current semantic segmentation methods mainly adopt an encoder-decoder architecture. The encoder usually consists of multiple hierarchically stacked feature extraction layers (e.g., the set abstraction layer) and extracts rich semantic features by reducing the resolution of its feature maps. Therefore, information loss is introduced and the segmentation performance is decreased.
Evaluation
Metric: mAcc and mIoU
Datasets
Synthia and SemanticKITTI
Result

Table 1. Semantic segmentation results on the Sythia dataset. Mean accuracy and mean IoU (%) are used as the evaluation metrics.

Table 2. Semantic segmentation results on the SemanticKITTI dataset. Per-class and average IoU (%) are used as the evaluation metrics. c1-c19 represent the 19 categories provided in the SemanticKITTI dataset, namely, car (c1), bicycle (c2), motorcycle (c3), truck (c4), other-vehicle (c5), person (c6), bicyclist (c7), motorcyclist (c8), road (c9), parking (c10), sidewalk (c11), other-ground (c12), building (c13), fence (c14), vegetation (c15), trunk (c16), terrain (c17), pole (c18), and traffic-sign (c19).
Method
For 4D semantic segmentation, which is a point-level classification task, our $PST^2$ model takes a multi-frame point cloud sequence as its input, and predicts the category of each point in the point cloud sequence. Our $PST^2$ model adopts an encoder-decoder architecture. Specifically, the encoder consists of a backbone, an RE module and an STSA module, and the decoder includes multiple Feature Propagation (FP) layers. The FP layer is originally introduced in PointNet++ to interpolate the semantic features extracted by the encoder upwards and predict the semantic category of each point.
As illustrated in Fig. 1 (a), given a point cloud sequence, three steps are adopted to capture point dynamics in our $PST^2$ model. First, we use a backbone network (including two set abstraction layers ) to construct the spatialtemporal neighborhoods and extract point features in each frame . Then, we adopt the proposed RE module to enhance the resolution of features in each frame. Finally, we employ the proposed STSA module to fuse the inter-frame features and produce the predictions
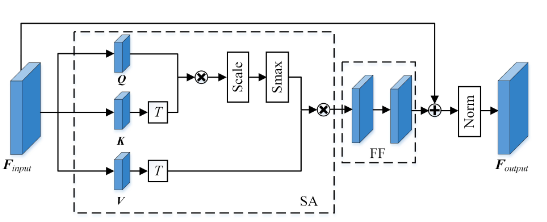
Figure 1. . In the 4D semantic segmentation task, we apply two set abstraction layers to extract features, and then employ the Resolution Embedding (RE) module to recover the lost geometric information of the extracted features. Next, we perform convolution on the features of adjacent frames to obtain spatial-temporal patches, and then fed these patches into a SpatioTemporal Self-Attention (STSA) module to capture spatial-temporal context information. Finally, we use multiple Feature Propagation (FP) layers to produce point-wise semantic predictions.
Spatial-Temporal Neighborhood Construction
Given a point cloud sequence $\lbrace S_t \rbrace_{t=1}^T$, each frame of the point cloud is represented as $S_t = \lbrace p_i^{(t)} \rbrace_{i=1}^n$ , where $n$ is the number of points.
We first sample the seed points in the first frame $S_1$, and groups all points within a certain radius around these seed points to form a neighborhood. Next, we use the same seed points in subsequent frames $\lbrace S_2, …, S_T \rbrace $ to construct spatial-temporal neighborhoods with stable spatial locations at different times.
Resolution Embedding (RE)
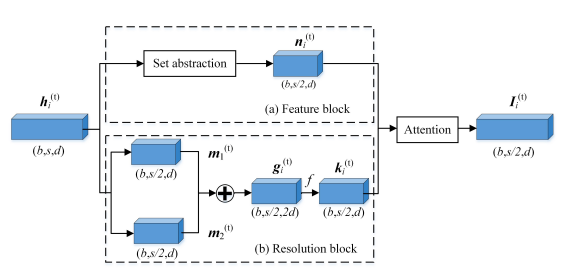
Figure 2. The architecture of our RE module. Attention and set abstraction stand for the attention operation and the set abstraction layer. b, s and d represent the batch size, spatial dimension, and feature dimension of the input features, respectively
Spatio-Temporal Self-Attention (STSA)
Given spatial features $I_i^{(t)}$ of each frame, the STSA module is used to incorporate inter-frame features along the temporal dimension and capture the spatio-temporal context information. Intuitively, different inter-frame spatialtemporal neighbors contribute differently to the final results. Specifically, for objects with slow-moving speeds, interframe spatial-temporal neighbors that are closer in space contributed more than those neighbors that are far apart. In contrast, for objects with fast-moving speeds, inter-frame spatial-temporal neighbors that are far in space should also be considered. Transformer-based methods have the potential to learn the correlation within inter-frame spatialtemporal neighborhoods. As shown in Fig. 3, our STSA module consists of two blocks: spatial-temporal patch division, and self-attention
Figure 3. The architecture of our STSA module. SA, Norm, Smax, T and FF stand for the self-attention operation, the layer normalization function, the softmax operation, the matrix transpose operation, and the feed-forward network, respectively.
Comments
Pros
Cons
(need further experiment)
Further work
Comments
(need further experiment)




