
Basic Information
Authors: Jianyun Xu, Zhenwei Miao, Da Zhang, Hongyu Pan, Kaixuan Liu, Peihan Hao, Jun Zhu, Zhengyang Sun, Hongmin Li, and Xin Zhan
Organization: Alibaba Group
Source: ECCV 2022
Source Code: https://github.com/ADLab-AutoDrive/INT
Cite: Xu, Jianyun, et al. “INT: Towards Infinite-Frames 3D Detection with an Efficient Framework.” Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX. Cham: Springer Nature Switzerland, 2022.
Content
Motivation
Current approaches require loading all the used frames at once during training, resulting in very limited frames being used due to computational, memory, or optimization difficulties. Taking the SOTA detector CenterPoint as an example, it only uses two frames on the Waymo Open Dataset. While increasing the number of frames can boost the performance, it also leads to significant latency burst as shown in Fig. 1. Memory overflow occurs if we keep increasing the frames of CenterPoint, making both training and inference impossible. As a result, we believe that the number of frames used is the bottleneck preventing multi-frame development, and we intend to break through this barrier first.
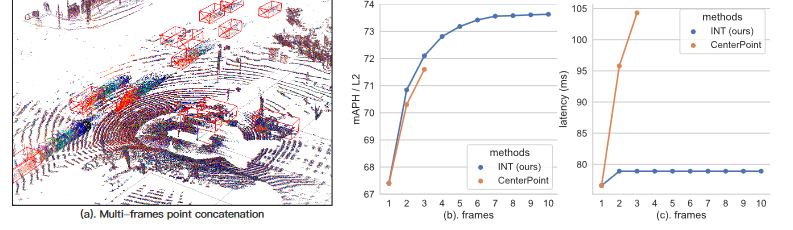
Figure 1. Impact of frames used in detectors on Waymo val set. While CenterPoint’s performance improves as the number of frames grows, the latency also increases dramatically. On the other hand, our INT keeps the same latency while increasing frames.
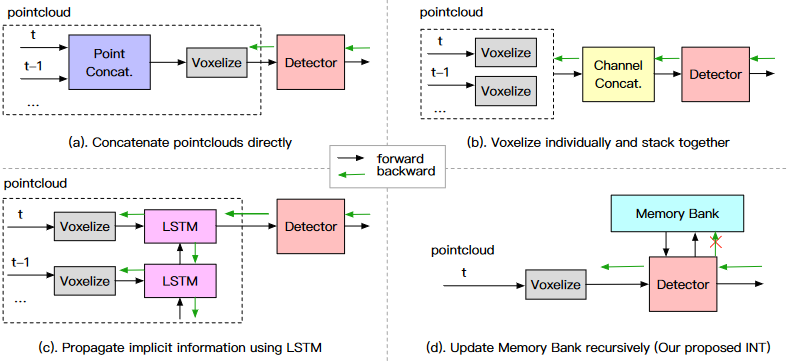
Figure 2. Training phase of different multi-frame schemes. Operations inside dash rectangle either involve repetitive computation or raise memory burden, which leads to a very limited frame number for training.
There are two major problems that limit the number of frames in a multiframe detector: 1) repeated computation. Most of the current multi-frame frameworks have a lot of repeated calculations or redundant data that causes computational spikes or memory overflow; 2) optimization difficulty. Some multi-frame systems have longer gradient conduction links as the number of frames increases, introducing optimization difficulties.
To alleviate the above problems, we propose INT (short for infinite), an on-stream system that theoretically allows training and prediction to utilize infinite number of frames. INT contains two primary components: 1) a Memory Bank (MB) for temporal information fusion and 2) a Dynamic Training Sequence Length (DTSL) strategy for on-stream training. The MB is a place to store the recursively updated historical information so that we don’t have to compute past frames’ features repeatedly. As a result, it only requires a small amount of memory but can fuse infinite data frames.
Evaluation
Metric: mAPH, latency
Datasets
Waymo, nuScenes
Result
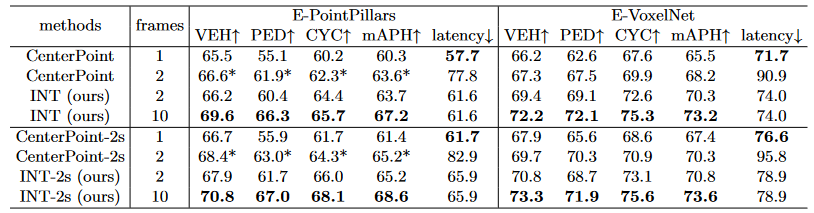
Table 2. Effectiveness and efficiency of INT on Waymo Open Dataset val set. The APH of L2 difficulty is reported. The ”-2s” suffix in the rows means two-stage model.
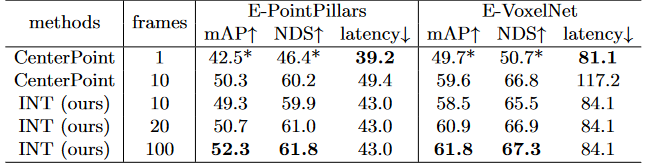
Table 2. Effectiveness and efficiency of INT on nuScenes val set. CenterPoint’s mAP and NDS results are obtained from official website, except for those with a *, which are missing from the official results and were reproduced by us.
Method
The INT framework in Fig. 2 is highly compact. The main body consists of a single-frame detector and a recursively updated Memory Bank (MB). The Dynamic Training Sequence Length (DTSL) below serves as a training strategy that is not needed for inference (inference only needs the pointclouds input in chronological order). In addition, there are no special requirements for singleframe detector selection. For example, any detector listed in Sec. 2.1 can be utilized.
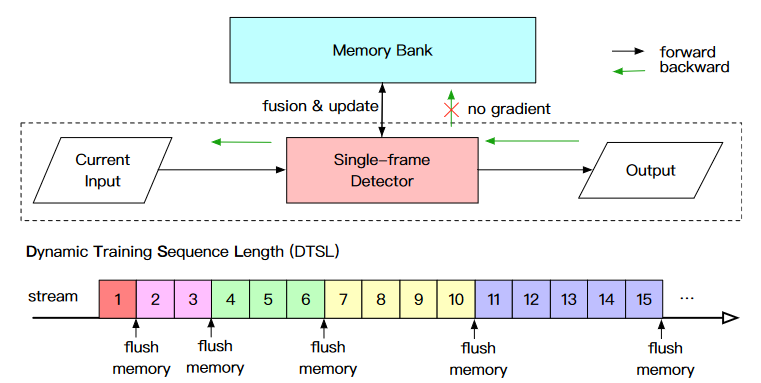
Figure 2. Overview of INT framework. It consists of a single-frame detector and a Memory Bank. The Dynamic Training Sequence Length below serves as a training strategy.
Memory Bank
The primary distinction between INT and a regular multi-frame detector is the MB, which stores historical data so that we do not have to compute past features repeatedly. MB is comparable to the hidden state in LSTM while it is more flexible, interpretable, and customizable. The user has complete control over where and what information should be saved or retrieved.
SeqFusion
Temporal fusion in the Memory Bank is critical in the INT framework. As the type of data in a 3D detector is either point-style or image-style, as indicated in Sec. 2.1, we develop both the point-style and image-style fusion algorithms. In general, original pointcloud, sparse voxel, predicted object, etc., fall into the point-style category. Whereas dense voxel, intermediate feature map, final prediction map, etc., fall into the image-style category.
Point-style fusion. Here we propose a general and straightforward practice: concatenating past point-style data with present data directly, using a channel to identify the temporal relationship. The historical point-style data is put into a fixed length FIFO queue, and as new observations arrive, foreground data is pushed into it, while oldest data is popped out. According to the poses of ego vehicle, the position information in the history data must be spatially transformed before fusion to avoid the influence of ego movement. The point-style fusion is formulated as:
\[T_{rel} = T_{cur}^{-1} \cdot T_{last}\] \[P_f = PointConcat(P_{cur}, T_{rel} \cdot P_{last})\]where $T_{last}$ and $T_{cur}$ are the last and current frame’s ego vehicle poses, respectively, while $T_{rel}$ is the calculated relative pose between the two frames. $P_{last}$ refers to the past point-style data in Memory Bank and $P_f$ is the fused data of $P_{last}$ and current $P_{cur}$.
Dynamic Training Sequence Length (DTSL).
A problem with INT training on stream is the information gained from the current observation is not derived using the same model parameters as the past data in the MB. This could lead to inconsistencies in training and prediction, which is one of the key reasons why prior multi-frame work was not trained on stream. To solve this problem, we offer the DTSL: beginning with a small sequence length and gradually increasing it, as indicated at the bottom of Fig. 3. This is based on the following observation: as the number of training steps increases, model parameter updates get slower, and the difference in information acquired from different model parameters becomes essentially trivial. As a result, when the model parameters are updated quickly, the training sequence should be short so that the Memory Bank can be cleaned up in time. Once the training is stable, the sequence length can be increased with confidence. DTSL could be defined in a variety of ways, one of which is as follows:
\[DTSL = max(1, [l_{max} \cdot min(1, max(0, 2\cdot \frac{ep_{cur}}{ep_{all}} - 0.5))])\]where $l_{max}$ is the maximum training sequence length, $ep_{cur}$ and $ep_{all}$ is current epoch and total epoch number, respectively.
SeqSampler
SeqSampler is the key to perform the training of INT in an infinite-frames manner. It is designed to split original sequences to target length, and then generate the indices of them orderly. If the sequence is infinite-long, the training or inference can go on infinitely. DTSL is formed by executing SeqSampler with different target lengths for each epoch.
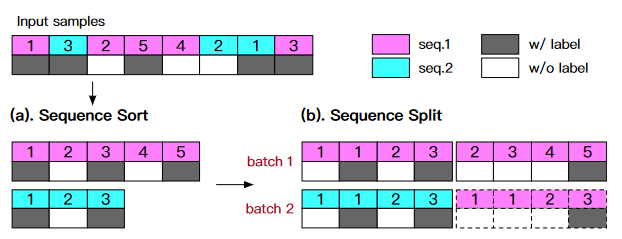
Figure 3. An example of SeqSampler. There are two sequences: seq1 contains 5 frames and seq2 has 3, both are interval labeled. Given the desired batch size 2 and target length 4, we need to get the final iteration indices. First, the two sequences are sorted separately. Then, the original sequences are splitted to 3 segments in the target length, and a segment is randomly replicated (dashed rectangles) to guarantee that both batches have the same number of samples.
The length of original sequences in a dataset generally varies, for as in the Waymo Open Dataset, where sequence lengths oscillate around 200. Certain datasets, such as nuScenes, may be interval labeled, with one frame labeled every ten frames. As a result, the SeqSampler should be designed with the idea that the source sequence will be non-fixed in length and will be annotated at intervals.
SeqAug
Sequence Point Transformation and Sequence GtAug.
Comments
Pros
Cons
Further work
Comments
(need further experiment)




