
Basic Information
Authors: Lukasz Dudziak, Stefanos Laskaridis, Javier Fernandez-Marques
Organization: Samsung AI Center
Source: arXiv
Source Code: None
Cite: Dudziak, Lukasz, Stefanos Laskaridis, and Javier Fernandez-Marques. “FedorAS: Federated Architecture Search under system heterogeneity.” arXiv preprint arXiv:2206.11239 (2022).
Content
Motivation
Neural Architecture Search (NAS) has become the de facto mechanism to automate the design of DNNs that can meet the requirements (e.g. latency, model size) for these to run on resource-constrained devices. The success of NAS can be partly attributed to the fact that these frameworks are commonly run in datacenters, where high-performing hardware and/or large curated datasets are available. However, this also imposes two major limitations on current NAS approaches: i) privacy, i.e. these methods were often not designed to work in situations when user’s data must remain on-device; and, consequently, ii) tail data non-discoverability, i.e. they might never be exposed to infrequent or time/user-specific data that exist in the wild but not necessarily in centralized datasets.
Motivated by the aforementioned phenomena and limitations of the existing NAS methods, we propose FedorAS, a system that performs NAS over heterogeneous devices holding heterogeneous data in a resource-aware and federated manner. To this direction, we cluster clients into tiers based on their capabilities and design supernet comprising operations covering the whole spectrum of compute complexities. This supernet acts both as search space and a weight-sharing backbone.
Upon federation, it is only partially and stochastically shared to clients, respecting their computational and bandwidth capabilities. In turn, we leverage resource-aware one-shot path sampling and adapt it to facilitate lightweight on-device NAS. In this way, networks in a given search space are not only deployed in a resource-aware manner, but also trained as such, by tuning the downstream communication and computation to meet the device’s training budget.
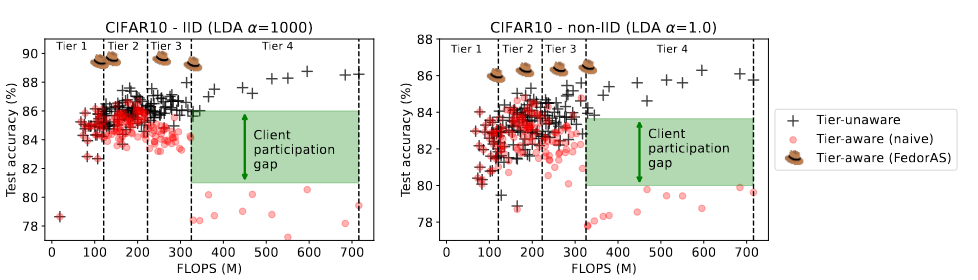
Figure 1. For three LDA settings, 160 architectures are randomly sampled from a ResNet-like search space and trained on a CIFAR-10 FL setup with 100 clients, with 10 clients participating on each round for a total of 500 rounds. Clients are uniformly assigned to a tier, resulting in 25 clients per tier. Given sufficient data and ignoring tier limits, model performance tends to improve as its footprint (FLOPS) increases (black crosses). However, when models are restricted to only train on clients that support them (tier-aware), the lack of data severely restricts the performance of more capable models (red dots).
Evaluation
Metric: Accuracy, FLOPs
Baselines: FedNAS, FjORD, SPIDER, ZeroFL, Oort, PyramidFL
Datasets
CIFAR-10/100, SpeechCommands, Shakespeare
Result
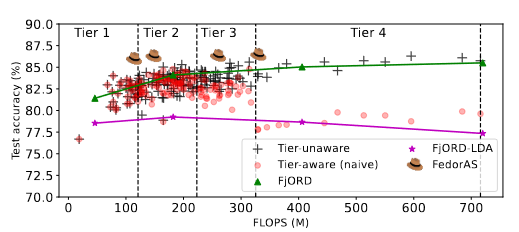
Figure 2. FedorAS outperforms other approaches. CIFAR-10 (non-IID, $\alpha = 1.0$). FjORD is represented as a line as it can switch between operating points on-the-fly via Ordered Dropout.
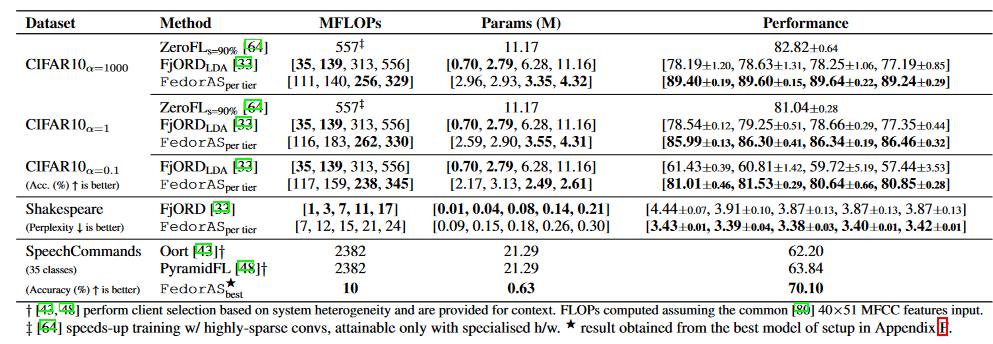
Table 1: Comparison with heterogeneous federated baselines. FedorAS performs better across datasets.
Challenges of Federated NAS. As highlighted before, devices in the wild exhibit different compute capabilities and can hold non-IID distributed data, resulting in system and data heterogeneity. In the context of NAS, system heterogeneity has a particularly significant effects, as we might no longer be able to guarantee that any model from our search space can be efficiently trained on all devices. This inability can be attributed to insufficient compute power, limited network bandwidth or unavailability of the client at hand. Consequently, some of the models might be deemed worse than others not because of their worse ability to generalise, but because they might not be exposed to the same subsets of data as others.
Method
FedorAS is a resource-aware Federated NAS framework that combines the best of both worlds: learning from clients across all tiers and yielding models tailored to each tier that benefit from this collective knowledge.
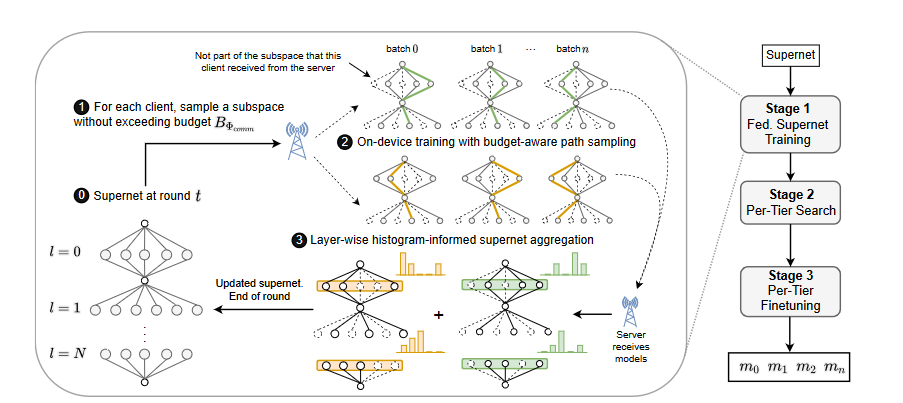
Figure 2: Training process workflow with FedorAS.
Workflow. FedorAS’ workflow consists of three stages (Fig. 2): i) supernet training, ii) model search and validation and iii) model fine-tuning. First, we train the supernet in a resource-aware and federated manner (Stage 1, Sec. 3.1). We then search for models from the supernet with the goal of finding the best architecture per tier (Stage 2, Sec. 3.2). Models are effectively sampled, validated on a global validation set and ranked per tier. These architectures and their associated weights act as initialisation to the next phase, where each model is fine-tuned in a per-tier manner (Stage 3. Sec. 3.3). The end goal of our system is to have the best possible model per each cluster of devices.
supernet training
First, we define the search space in terms of a range of operators options per layer in the network that are valid choices to form a network. This search space resides as a whole on the server and is only partially communicated to participating clients of a training round to keep communication overheads minimal.
Comments
Pros
Cons
(need further experiment)
Further work
Comments
(need further experiment)




