
Basic Information
Authors: Zetong Yang, Yin Zhou, Zhifeng Chen, Jiquan Ngiam
Organization: The Chinese University of Hong Kong, Waymo LLC, Google Research
Source: CVPR 2021
Source Code: None
Cite: Yang, Zetong, et al. “3d-man: 3d multi-frame attention network for object detection.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
Content
Motivation
LiDAR provides a high-resolution accurate 3D view of the world. However, at any point of time, the LiDAR sensor collects only a single perspective of the scene. It is often the case that the LiDAR points detected on an observed object correspond to only a partial view of it. Detecting these partially visible instances is an ill-posed problem because there exist multiple reasonable predictions(shown as red and blue boxes in the upper row of Figure 1). These potential ambiguous scenarios can be a bottleneck for single-frame 3D detectors (Table 1).
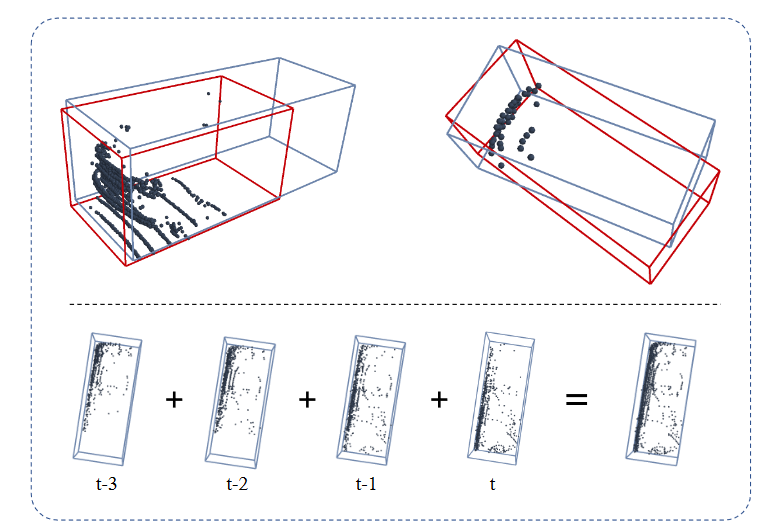
Figure 1. Upper row: Potential detections given LiDAR from a single frame demonstrating ambiguity between many reasonable predictions. Lower row: After merging the points aligned across 4 frames, there is more certainty for the correct box prediction.

Table 1. We vary the intersection-over-union (IoU) threshold for considering a predicted box correctly matched to a ground-truth box, and measure the performance of the PointPillars model on the Waymo Open Dataset’s validation set. A lower IoU threshold corresponds to allowing less accurate boxes to match. This shows that improving the box localization could significantly improve model performance.
A straight-forward approach to fusing multi-frame point clouds is to use point concatenation, which simply combines points across different frames together. However, when objects are fast-moving or when longer time horizons are considered, this approach may not be as effective since the LiDAR points are no longer aligned (Table 2).

Table 2. Velocity breakdowns of vehicle AP metrics for PointPillars models using point concatenation. For the 8-frame model, we find that its benefits come from slow-moving vehicles. Fastmoving objects no longer benefit from a large number of frames since the LiDAR points are no longer aligned across the frames.
Recent approaches propose using recurrent layers such as Conv-LSTM or Conv-GRU to aggregate the information across frames. It turns out that these recurrent approaches are often computationally expensive.
We propose 3D-MAN: a 3D multi-frame attention network that is able to extract relevant features from past frames and aggregate them effectively. 3D-MAN has three components: (i) a fast single-frame detector, (ii) a memory bank, and (iii) a multi-view alignment and aggregation module.
Evaluation
Metric: 3D AP (IoU=0.7) 3D APH (IoU=0.7)
Datasets
Waymo Validation Set. Waymo Testing Set.
Result
Table 3. 3D AP and APH Results on Waymo Open Dataset validation set for class Vehicle. ∗Methods utilize multi-frame point clouds for detection. We report PointPillars based on our own implementation, with and without point concatenation. Difficulty levels are defined in the original dataset.
Method
The 3D-MAN framework (Figure 2) consists of 3 components: (i) a fast single-frame detector (FSD) for producing proposals given input point clouds, (ii) a memory bank to store features from different frames and (iii) a multi-view alignment and aggregation module (MVAA) for combining information across frames to generate final predictions.
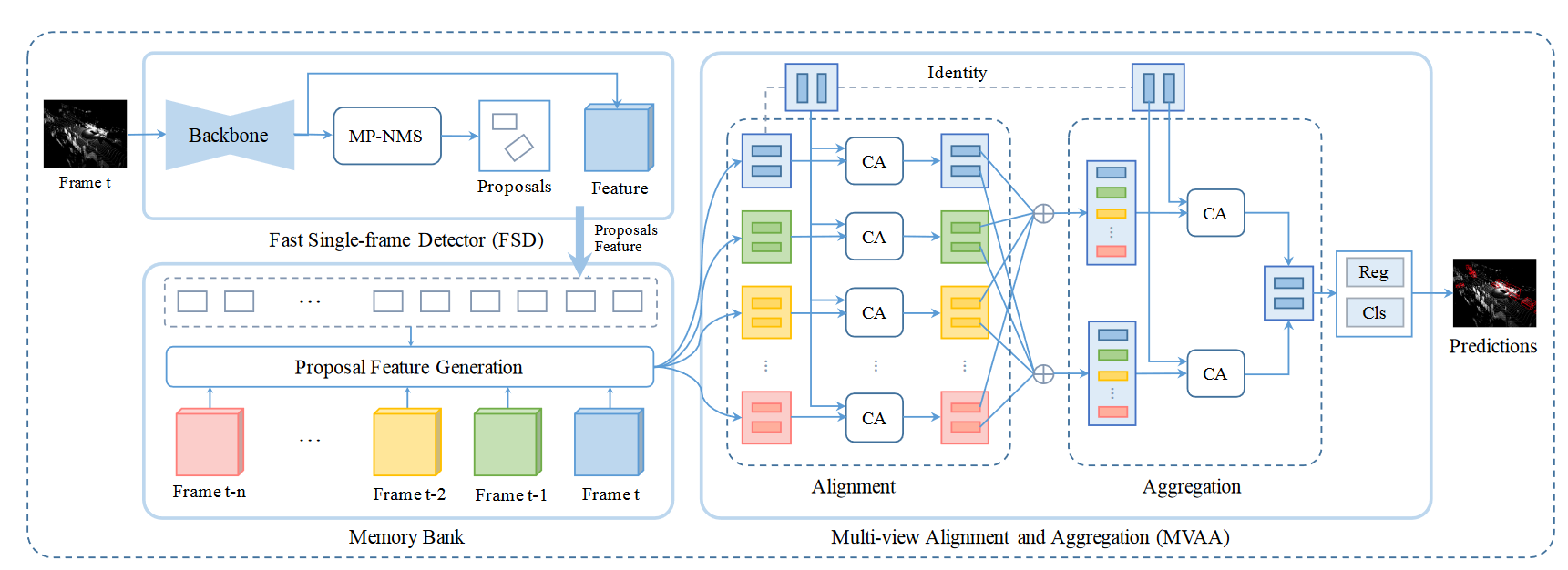
Figure 2. Framework for 3D-MAN: 3D multi-frame attention network. Given the point cloud for a target frame t, a fast single-frame detector first generates box proposals. These proposals (box parameters) with the feature map (last layer of the backbone network) are inserted into a memory bank that stores proposals and features for the last n frames. We use a proposal feature generation module to extract proposal features for each stored frame. Each small rectangle box denotes a proposal and its associated features extracted in different frames. The multi-view alignment and aggregation module performs attention across proposal features from the memory bank, using the target frame as queries to extract features for classification and regression. “MP-NMS” and “CA” represent MaxPoolNMS and cross-attention respectively. During training, we use classification and regression losses applied to the FSD proposals (Lfsd), the final outputs of the MVAA network (Lmvaa), and the outputs of the alignment stage (Lcv, an auxiliary cross-view loss).
Fast Single-frame Detector
Anchor-free Point Pillars. We base our single-frame detector on the PointPillars architecture with dynamic voxelization. We start by dividing the 3D space into equally distributed pillars which are voxels of infinite height. Each point in the point cloud is assigned to a single pillar.
Each location of the final layer of the network produces a prediction for a bounding box relative to the corresponding pillar center. We regress the location residuals, bounding box sizes, and orientation. A binning approach is used for predicting orientation which first classifies the orientation into one bin followed by regression of the residual from the corresponding bin center.
Non-maximum suppression (NMS) is often used to postprocess the detections produced by the last layer of the netork for redundancy removal. However, the sequential nature of this algorithm makes it slow to run in practice when there is a large number of predictions. We use a variant of NMS that leverages maxpooling to speed up this process. MaxPoolNMS [1] uses the max pooling operation to find local peaks on the objectness score map. The local peaks are kept as predictions, while all other locations are suppressed.
Hungarian Matching. I do not understand.
Memory Bank
Memory Bank. We use a memory bank to store the proposals and feature maps extracted by the FSD for the last n frames. When proposals and features from a new frame are added to the bank, those from the oldest frame are discarded.
Proposal Feature Generation. To obtain features from multiple perspectives, we propose to generate proposal features for each stored frame in the memory bank as well as the target frame.
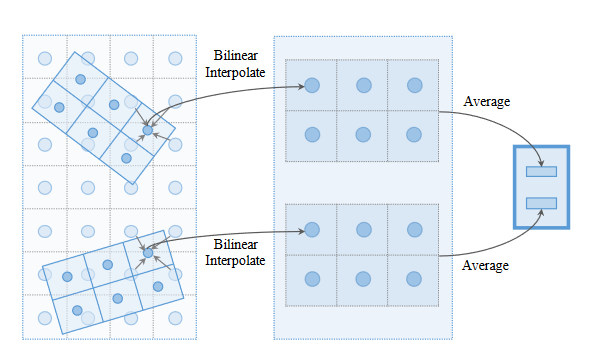
Illustration of rotated ROI feature extraction [13]. We first identify key points in each proposal box and then extract features using bilinear interpolation. Averaging pooling is further used to summarize each box into a single feature vector. Note that while the figure denotes key points over 3 × 2 locations, we use 7 × 7 for vehicles and 3 × 3 for pedestrians.
Multi-view Alignment and Aggregation
These proposal features are then sent to the multi-view alignment and aggregation module (MVAA) to be extracted and aggregated. The alignment module is applied independently for each stored frame (attention is across boxes, performed separately for each frame), while the aggregation module is applied independently for each box (attention is across time). One can view this as a factorized form of attention.
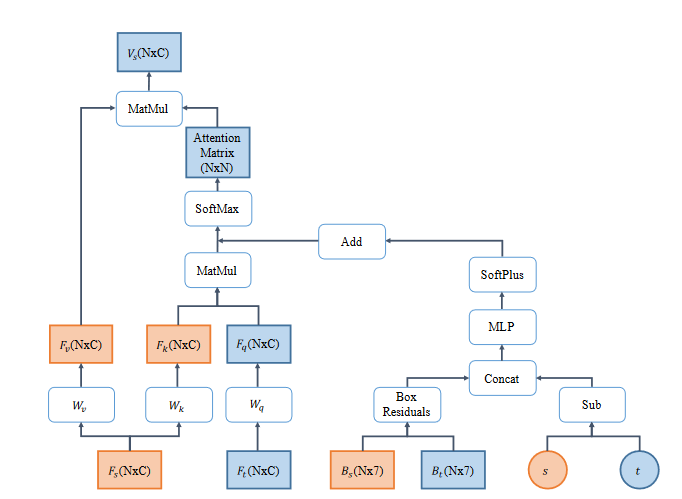
Cross-attention network in the multi-view alignment module. $F_s$ and $B_s$ represent features and box parameters of proposals in a stored frame while Ft and Bt are those for the target frame. We use $s$ and $t$ to denote the indices of the stored frame and target frame respectively. $N$ and $C$ stand for the number of proposals and channels. “Box residuals” produces a pairwise $N \times N \times 7$ tensor that encodes the differences in all pairs of boxes, using the same approach that is used to compute residuals for ground-truth boxes from anchor boxes. Vs is the output of the cross-attention network, such that each input target box has one associated output feature vector with the corresponding stored frame.
Multi-view Alignment.
Given a new frame’s proposal, the multi-view alignment module is responsible for extracting its relevant information in each previous frame separately
A naive approach could use nearest neighbor matching or maximum IoU overlap. However, when an instance is fast-moving or close to any other instance, there will often be ambiguity in the appropriate assignment.
We propose using a cross-attention network (Figure 4) to learn how to relate the new frame proposals to those of stored frames. This network could potentially learn to align the proposal identities and also model interactions across objects.
Cross-view Loss.
The alignment stage of MVAA is designed to extract features from each stored frame that are most relevant to each target proposal. To encourage the extracted features to be a relevant representation, we employ an auxiliary loss that encourages the extracted features to contain sufficient information to predict the corresponding ground-truth bounding box associated with the target proposal.
Multi-view Aggregation.
After the alignment module, each proposal in the target frame will have an associated feature for each stored frame. The multi-view aggregation layer (Figure 2, MVAA-Aggregation) is responsible for combining these features from different perspectives together to form a single feature for each proposal. Concretely, we use the new frame’s proposal features as the attention query inputs, and its corresponding extracted features in previous frames as the keys and values
Box Prediction Head.
After MVAA, we have an updated feature for each proposal in the new frame. We regress objectness scores and box parameters from this feature representation.
Comments
Pros
- Propose a good problem, ill pose problem
Cons
- Fast Single-frame Detector can not provide correct proposals
- Proposed Feature are highly compressed, loss a lot of information
- may suffer from overlapping problem.
Further work
(need further experiment)
Comments
(need further experiment)
References
[1] Xingyi Zhou, Dequan Wang, and Philipp Krahenbuhl. Objects as points. CoRR, 2019. 4, 8




