
Basic Information
Authors: Runsheng Xu, Zhengzhong Tu, Hao Xiang, Wei Shao, Bolei Zhou, Jiaqi Ma
Organization: University of California, Los Angeles; University of Texas at Austin; University of California, Davis
Source: CoRL 2022
Source Code: https://github.com/DerrickXuNu/CoBEVT
Cite: Xu, R., Tu, Z., Xiang, H., Shao, W., Zhou, B., & Ma, J. CoBEVT: Cooperative Bird’s Eye View Semantic Segmentation with Sparse Transformers. In 6th Annual Conference on Robot Learning.
Content
Motivation
Several prior works have demonstrated the efficacy of cooperative perception utilizing LiDAR sensors. Nevertheless, whether, when, and how this V2V cooperation can benefit camera-based perception systems has not been explored yet
In this paper, we present CoBEVT, the first-of-its-kind framework that employs multi-agent multicamera sensors to generate BEV segmented maps via sparse vision transformers cooperatively. Fig. 1 illustrates the proposed framework. Each AV computes its own BEV representation from its camera rigs with the SinBEVT Transformer and then transmits it to others after compression. The receiver (i.e. other AVs) transforms the received BEV features onto its coordinate system, and employs the proposed FuseBEVT for BEV-level aggregation. The core ingredient of these two transformers is a novel fused axial attention (FAX) module, which can search over the whole BEV or camera image space across all agents or camera views via local and global spatial sparsity. FAX contains global attention to model long-distance dependencies, and local attention to aggregate regional detailed features, with low computational complexity
Evaluation
Metric: AP@0.7
Details: We assume all the AVs have a 70m communication range, and all the vehicles out of this broadcasting radius of ego vehicle will not have any collaboration.
Baselines: F-Cooper, AttFuse, V2VNet, and DiscoNet.
Datasets
OPV2V and nuScenes
Result
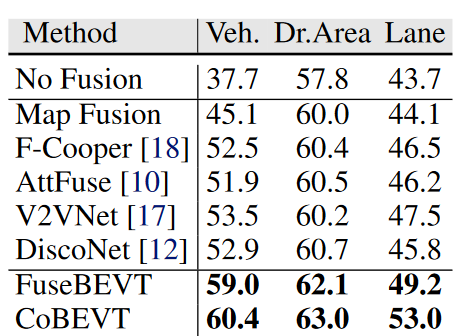
Table 1. Map-view segmentation on OPV2V camera-track. We report IoU for all classes. All fusion methods employs CVT backbone, except for CoBEVT which uses SinBEVT backbone.
Method
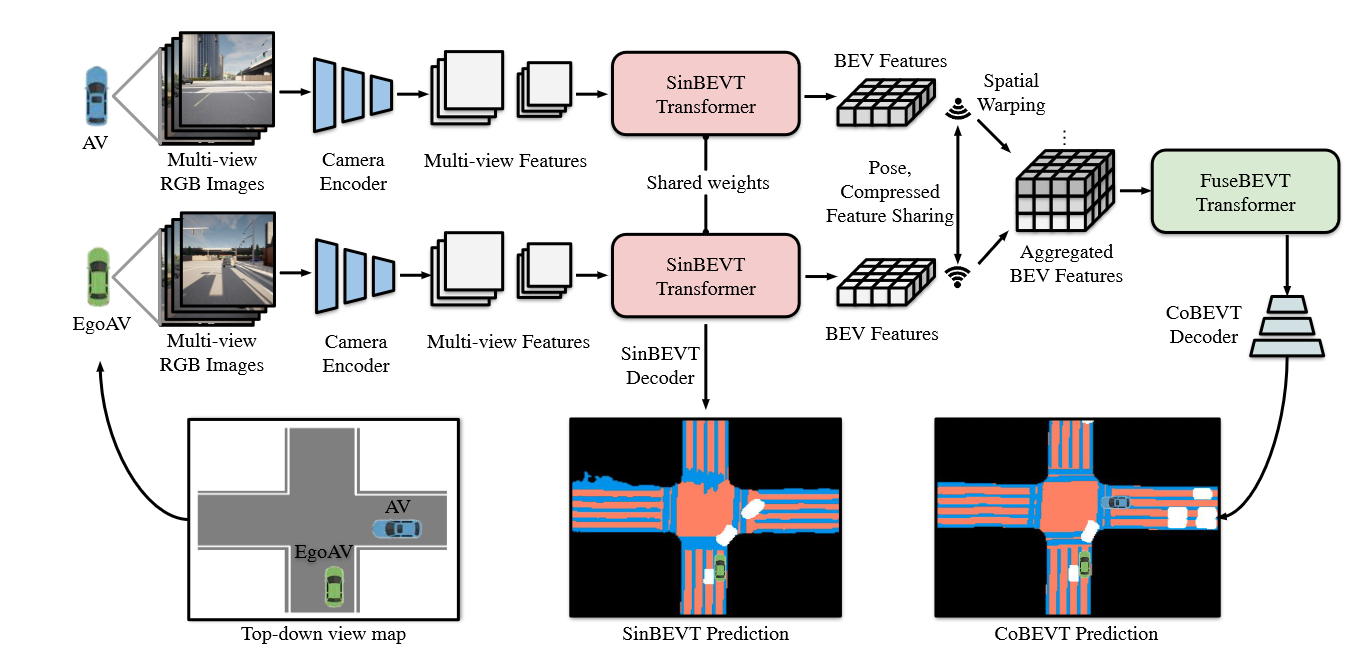
Figure 1: The overall framework of CoBEVT. White boxes in prediction maps indicate car segmentation results.
The overall architecture of CoBEVT is illustrated in Fig. 1, which consists of: SinBEVT for BEV feature computation , feature compression and sharing, and FuseBEVT for multi-agent BEV fusion. We propose a novel 3D attention mechanism called fused axial attention (FAX) as the core component of SinBEVT and FuseBEVT that can efficiently aggregate features across agents or camera views both locally and globally.
Fused Axial Attention (FAX)
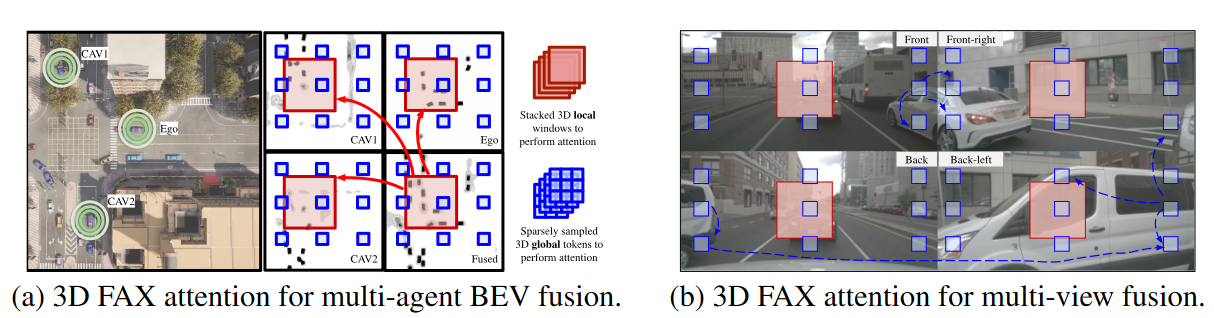
Figure 2: Illustrated examples of fused axial attention (FAX) in two use cases – (a) multi-agent BEV fusion and (b) multi-view camera fusion. FAX attends to 3D local windows (red) and sparse global tokens (blue) to attain location-wise and contextual-aware aggregation. In (b), for example, the white van is torn apart in three views (front-right, back, and back-left), our sparse global attention can capture long-distance relationships across parts in different views to attain global contextual understanding.
On the one hand, neighboring AVs often have different occlusion levels on the same object; hence, local attention, which cares more about details, can help construct pixel-to-pixel correspondence on that object. Take the scene in Fig. 2(a) as an example. The ego vehicle should aggregate all the BEV features per location from nearby AVs to obtain reliable estimates. On the other hand, long-term global contextual awareness can also assist in understanding the road topological semantics or traffic states – the road topology and traffic density ahead of the vehicle are often highly correlated with the one behind. This global reasoning is also beneficial for multi-camera views understanding. In Fig. 2(b), for instance, the same vehicle is torn apart into multi-views, and global attention is highly capable of connecting them for semantic reasoning.
To attain such local-global properties efficiently, we propose a sparse 3D attention model called fused axial attention (FAX), which performs both local window-based attention and sparse global interactions.
Let $X \in R ^{N \times H \times W \times C}$ be the stacked BEV features with spatial dimension $H \times W$ from $N$ agents. In the local branch, we partition the feature map into 3D non-overlapping windows, each of size $N \times P \times P$. The partitioned tensor of shape $(\frac{H}{P} \times \frac{W}{P}, N \times P^2, C)$ is then fed into the self-attention model, representing mixing information along the second axis i.e., within local 3D windows. Likewise, in the global branch, feature $X$ is divided using a uniform 3D grid $N \times G \times G$ into the shape $(N \times G^2, \frac{H}{G} \times \frac{W}{G} , C)$. Employing attention on the first axis of this tensor representing attending to sparsely sampled tokens. Fig. 2 illustrates the attended regions using red and blue colored boxes for local and global branches, respectively. The 3D FAX selfattention (FAX-SA) block can be expressed as:
\[\hat{z}^{\ell}=3\mathrm{DLAttn}(\mathrm{LN}(z^{\ell-1}))+z^{\ell-1}, \qquad\qquad\qquad z^{\ell}=\mathrm{MLP}(\mathrm{LN}(\hat{z}^{\ell}))+\hat{z}^{\ell},\] \[\hat{z}^{\ell+1}=3\mathrm{DGAttn(LN(z^{\ell}))}+z^{\ell},\qquad\qquad z^{\ell+1}=\mathrm{MLP(LN(\hat{z}^{\ell}))+\hat{z}^{\ell},}\]where $\hat{z}^{\ell}$ and $z^{\ell}$ denote the output features of the $3\mathrm{DL(G)Attn}$ module and MLP module for block $\ell$, The 3DLAttn and 3DGAttn represent the above-defined 3D local and global attention, respectively.
SinBEVT for Single-agent BEV Feature Computation
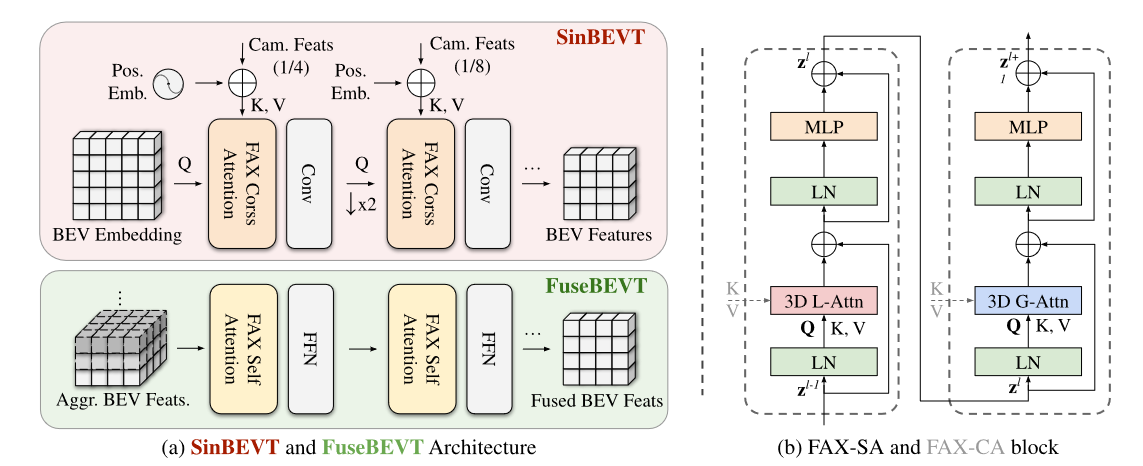
Figure 3: Architectures of (a) SinBEVT and FuseBEVT, and (b) the FAX-SA and FAX-CA block.
Comments
Pros
- propose a holistic vision Transformer dubbed CoBEVT for multi-view cooperative semantic segmentation.
Cons
(need further experiment)
Further work
(need further experiment)
Comments
(need further experiment)




