
Basic Information
Authors: Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma
Organization: University of California, Los Angeles; University of Texas at Austin; Google Research; University of California, Merced
Source: ECCV 2022
Source Code: https://github.com/DerrickXuNu/v2x-vit
Content
Motivation
Although V2V technologies have the prospect to revolutionize the mobility industry, it ignores a critical collaborator – roadside infrastructure. The presence of AVs is usually unpredictable, whereas the infrastructure can always provide supports once installed in key scenes such as intersections and crosswalks.
Unlike V2V collaboration, where all agents are homogeneous, V2X systems often involve a heterogeneous graph formed by infrastructure and AVs. The configuration discrepancies between infrastructure and vehicle sensors, such as types, noise levels, installation height, and even sensor attributes and modality, make the design of a V2X perception system challenging.
In this paper, we introduce a unified fusion framework, namely V2X Vision Transformer or V2X-ViT, for V2X perception, that can jointly handle these challenges. We propose two novel attention modules to accommodate V2X challenges: 1) a customized heterogeneous multi-agent self-attention module that explicitly considers agent types (vehicles and infrastructure) and their connections when performing attentive fusion; 2) a multi-scale window attention module that can handle localization errors by using multi-resolution windows in parallel.
Evaluation
Evaluation metrics. The detection performance is measured with Average Precisions (AP) at Intersection-over-Union (IoU) thresholds of 0.5 and 0.7. Implementation details. During training, a random AV is selected as the ego vehicle, while during testing, we evaluate on a fixed ego vehicle for all the compared models.
Datasets
Self-built dataset, V2XSet, a new large-scale dataset for V2X perception that explicitly considers these real-world noises during V2X collaboration using CARLA and OpenCDA together. In total, there are 11,447 frames in our dataset (33,081 samples if we count frames per agent in the same scene), and the train/validation/test splits are 6,694/1,920/2,833, respectively.
Result
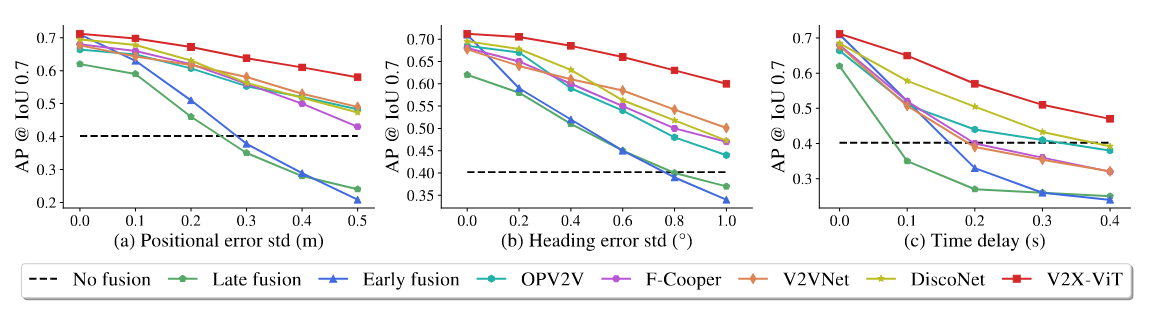
Figure 1. Robustness assessment on positional and heading errors.
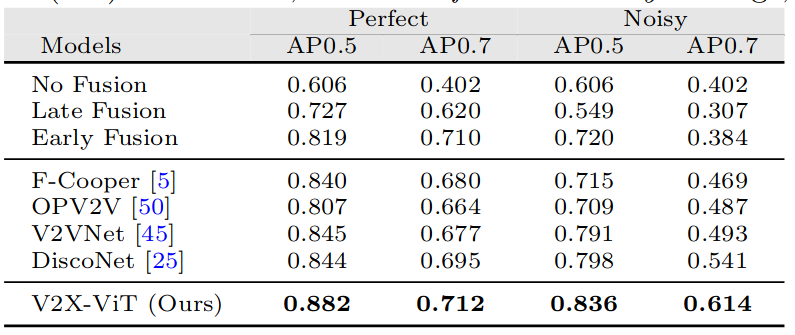
Table 1. 3D detection performance comparison on V2XSet.
Method
In this paper, we consider V2X perception as a heterogeneous multi-agent perception system, where different types of agents (i.e., smart infrastructure and AVs) perceive the surrounding environment and communicate with each other. The overall architecture of our framework is illustrated in Fig. 2, which includes five major components: 1) metadata sharing, 2) feature extraction, 3) compression and sharing, 4) V2X vision Transformer, and 5) a detection head.
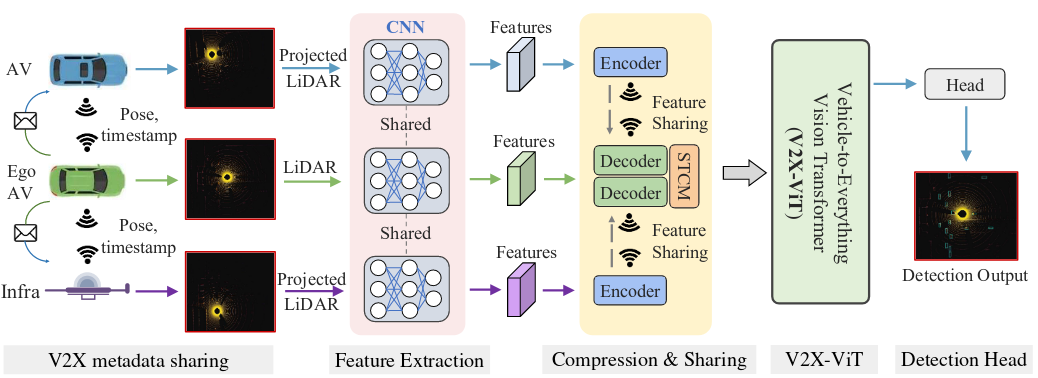
Overview of our proposed V2X perception system. It consists of five sequential steps: V2X metadata sharing, feature extraction, compression & sharing, V2X-ViT, and the detection head.
Main architecture design
V2X metadata sharing.
V2X metadata sharing. During the early stage of collaboration, every agent $i \in \lbrace1,\dots,N\rbrace$ within the communication networks shares metadata such as poses, extrinsics, and agent type $c_i \in \lbrace I, V\rbrace$ (meaning infrastructure or vehicle) with each other. Upon receiving the pose of the ego vehicle, all the other connected agents nearby will project their own LiDAR point clouds to the ego-vehicle’s coordinate frame before feature extraction.
Feature extraction.
We leverage the anchor-based PointPillar method to extract visual features from point clouds because of its low inference latency and optimized memory usage. The backbone extracts informative feature maps $F_i^{t_i} \in R^{H \times W \times C}$ denoting agent $i$’s feature at time $t_i$ with height $H$, width $W$ , and channels $C$.
There exists an inevitable time gap between the time when the LiDAR data is captured by connected agents and when the extracted features are received by the ego vehicle. To correct this delay-induced global spatial misalignment, we need to transform (i.e., rotate and translate) the received features to the current egovehicle’s pose. Thus, we leverage a spatial-temporal correction module (STCM), which employs a differential transformation and sampling operator $\Gamma_\xi$ to spatially warp the feature maps An ROI mask is also calculated to prevent the network from paying attention to the padded zeros caused by the spatial warp.
V2X-ViT
The intermediate features $H_i = \Gamma_\xi(F_i^{t_i}) \in R^{H\times W\times C}$ aggregated from connected agents are fed into the major component of our framework i.e., V2X-ViT to conduct an iterative inter-agent and intra-agent feature fusion using self-attention mechanisms.
Detection head.
After receiving the final fused feature maps, we apply two 1×1 convolution layers for box regression and classification. The regression output is $(x, y, z, w, l, h, \theta)$, denoting the position, size, and yaw angle of the predefined anchor boxes, respectively.
V2X-Vision Transformer
Our goal is to design a customized vision Transformer that can jointly handle the common V2X challenges. Firstly, to effectively capture the heterogeneous graph representation between infrastructure and AVs, we build a heterogeneous multiagent self-attention module that learns different relationships based on node and edge types. Moreover, we propose a novel spatial attention module, namely multi-scale window attention (MSwin), that captures long-range interactions at various scales. MSwin uses multiple window sizes to aggregate spatial information, which greatly improves the detection robustness against localization errors. Lastly, these two attention modules are integrated into a single V2X-ViT block in a factorized manner(illustrated in Fig. 3a), enabling us to maintain high resolution features throughout the entire process.
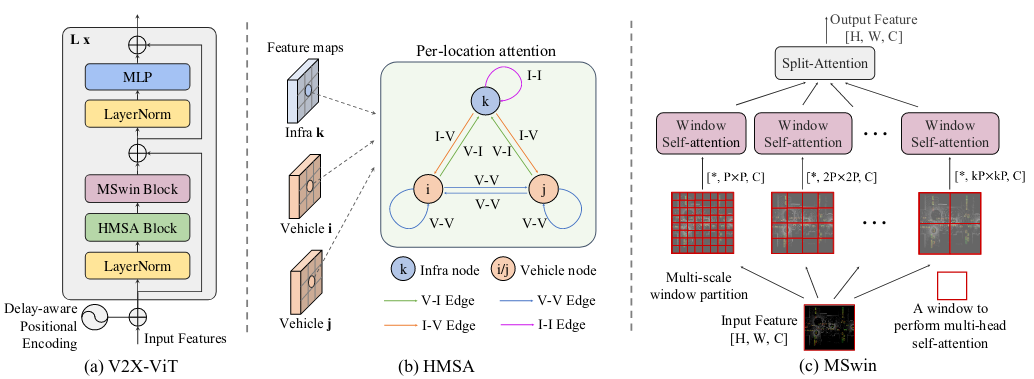
**V2X-ViT architecture.** (a) The architecture of our proposed V2X-ViT model. (b) Heterogeneous multi-agent self-attention (HMSA) (c) Multi-scale window attention module (MSwin)
Heterogeneous multi-agent self-attention(HHSA)
As shown in Fig. 3b, we have two types of nodes and four types of edges, i.e., node type $c_i \in \lbrace I, V \rbrace$ and edge type $\phi (e_{ij}) ∈ \lbrace V −V, V −I, I −V, I −I \rbrace$. Note that unlike traditional attention where the node features are treated as a vector, we only reason the interaction of features in the same spatial position from different agents to preserve spatial cues. Formally, HSMA is expressed as:
\[H_i = Dense_{c_i}(ATT(i, j) \cdot MSG(i, j)), \quad for \quad \forall j \in N(i)\]which contains 3 operators: a linear aggregator Denseci , attention weights estimator $ATT$, and message aggregator $MSG$. The Dense is a set of linear projectors indexed by the node type $c_i$, aggregating multi-head information. ATT calculates the importance weights between pairs of nodes conditioned on the associated node and edge types:
\[ATT(i, j) = softmax_{\forall j \in N(i)}(\|_{m\in[1,h]} head^m_{ATT}(i, j))\] \[head^m_{ATT}(i, j)) = (K^m(j)W^{m, ATT}_{\phi(e_{i,j})}Q^m(i)^T) \frac{1}{\sqrt{C}}\] \[K^m(j) = Dense_{c_j}^m(H_j)\] \[Q^m(i) = Dense_{c_i}^m(H_i)\]where $|$ denotes concatenation, m is the current head number and $h$ is the total number of heads. To incorporate the semantic meaning of edges, we calculate the dot product between Query and Key vectors weighted by a matrix $W_{\phi(e_{i,j})}^{m, ATT} \in R^{C \times C}$. Similarly, when parsing messages from the neighboring agent, we embed infrastructure and vehicle’s features separately via $Dense_{c_i}^m$. A matrix $W_{\phi(e_{i,j})}^{m, MSG}$ is used to project the features based on the edge type between source node and target node:
\[MSG(i, j) = \|_{m\in[1,h]} head^m_{MSG}(i, j)\] \[head^m_{MSG}(i, j) = Dense_{c_j}^m(H_j) W_{\phi(e_{i,j})}^{m, MSG}\]Multi-scale window attention
Multi-scale window attention (MSwin) uses a pyramid of windows, each of which caps a different attention range, as illustrated in Fig. 3c. The usage of variable window sizes can greatly improve the detection robustness of V2X-ViT against localization errors. Attention performed within larger windows can capture long-range visual cues to compensate for large localization errors, whereas smaller window branches perform attention at finer scales to preserve local context.
Notably, unlike Swin Transformer, our multi-scale window approach requires no masking, padding, or cyclic-shifting, making it more efficient in implementations while having larger-scale spatial interactions.
Delay-aware positional encoding
To encode this temporal information, we leverage an adaptive delay-aware positional encoding (DPE), composed of a linear projection and a learnable embedding. We initialize it with sinusoid functions conditioned on time delay $\Delta t_i$ and channel $c \in [1, C]$:
\[p_c(\Delta t_i) = \begin{cases} sin(\Delta t_i/10000^{\frac{2c}{C}}), & c = 2k \\ cos(\Delta t_i/10000^{\frac{2c}{C}}), & c = 2k+1 \end{cases}\]A linear projection $f: R^C \rightarrow R^C$ will further warp the learnable embedding so it can generalize better for unseen time delay. We add this projected embedding to each agents’ feature $H_i$ before feeding into the Transformer so that the features are temporally aligned beforehand.
\[H_i = H_i + f(p(\Delta t_i))\]Comments
Pros
- considering data hetergenous issue and time delay issue
- rubust
- ViT make sense
Cons
- too complex and I worry about computation cost
Further work
lightweight transformer
Comments
(need further experiment)




