
Basic Information
Authors: Xuyang Bai, Zeyu Hu, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, Chiew-Lan Tai
Organization: Hong Kong University of Science and Technology, ADS, IAS BU, Huawei, City University of Hong Kong
Source: IEEE/CVF Conference on Computer Vision and Pattern Recognition.(CVPR 2022)
Source Code: https://github.com/XuyangBai/TransFusion
Content
Motivation
Existing LiDAR-camera fusion methods roughly fall into three categories: result-level, proposal-level, and pointlevel. The result-level methods use off-the-shelf 2D detectors to seed 3D proposals. The proposal-level fusion methods perform fusion at the region proposal level by applying RoIPool in each modality for shared proposals. These coarse-grained fusion methods show unsatisfactory results since rectangular regions of interest (RoI) usually contain lots of background noise. Recently, a majority of approaches have tried to do point-level fusion and achieved promising results. They first find a hard association between LiDAR points and image pixels based on calibration matrices, and then augment LiDAR features with the segmentation scores or CNN features of the associated pixels through point-wise concatenation.
Despite the impressive improvements, these point-level fusion methods suffer from two major problems, as shown in Fig. 1. First, they simply fuse the LiDAR features and image features through element-wise addition or concatenation, and thus their performance degrades seriously with low-quality image features. Second, finding the hard association between sparse LiDAR points and dense image pixels not only wastes many image features with rich semantic information, but also heavily relies on high-quality calibration between two sensors. Our key idea is to reposition the focus of the fusion process, from hard-association to soft-association, leading to the robustness against degenerated image quality and sensor misalignment.

Figure 1. Left: An example of bad illumination conditions. Right: Due to the sparsity of point clouds, the hard-association based fusion methods waste many image features and are sensitive to sensor calibration, since the projected points may fall outside objects due to a small calibration error.
Evaluation
Metrics. mean Average Precision (mAP) and nuScenes detection score (NDS).
Datasets
nuScenes and Waymo Open Dataset.
Result
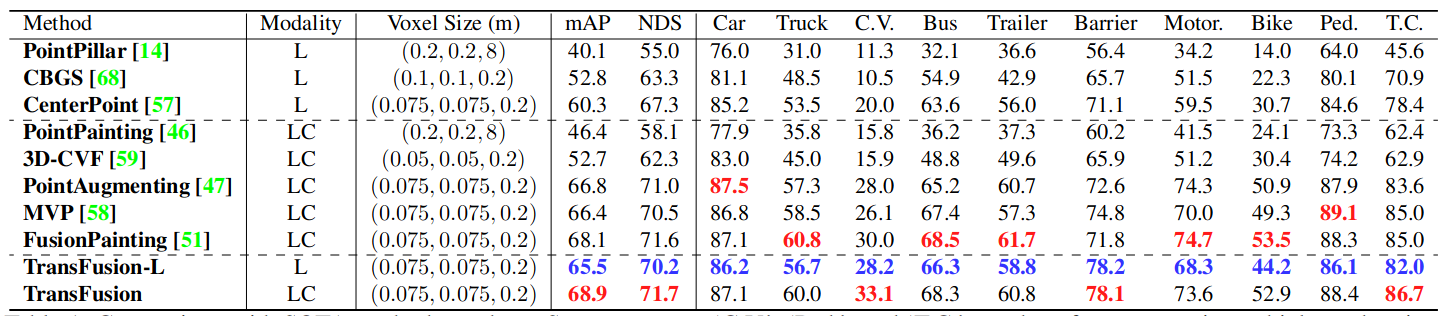
Table 1. Comparison with SOTA methods on the nuScenes test set. ‘C.V.’, ‘Ped.’, and ‘T.C.’ are short for construction vehicle, pedestrian, and traffic cone, respectively. ‘L’ and ‘C’ represent LiDAR and Camera, respectively. The best results are in boldface (Best LiDAR-only results are marked blue and best LC results are marked red). For FusionPainting, we report the results on the nuScenes website, which are better than what they reported in their paper. Note that CenterPoint and PointAugmenting utilize double-flip testing while we do not use any test time augmentation.
Method
In this section, we present the proposed method TransFusion for LiDAR-camera 3D object detection. As shown in Fig. 2, given a LiDAR BEV feature map and an image feature map from convolutional backbones, our transformerbased detection head first decodes object queries into initial bounding box predictions using the LiDAR information, and then performs LiDAR-camera fusion by attentively fusing object queries with useful image features.
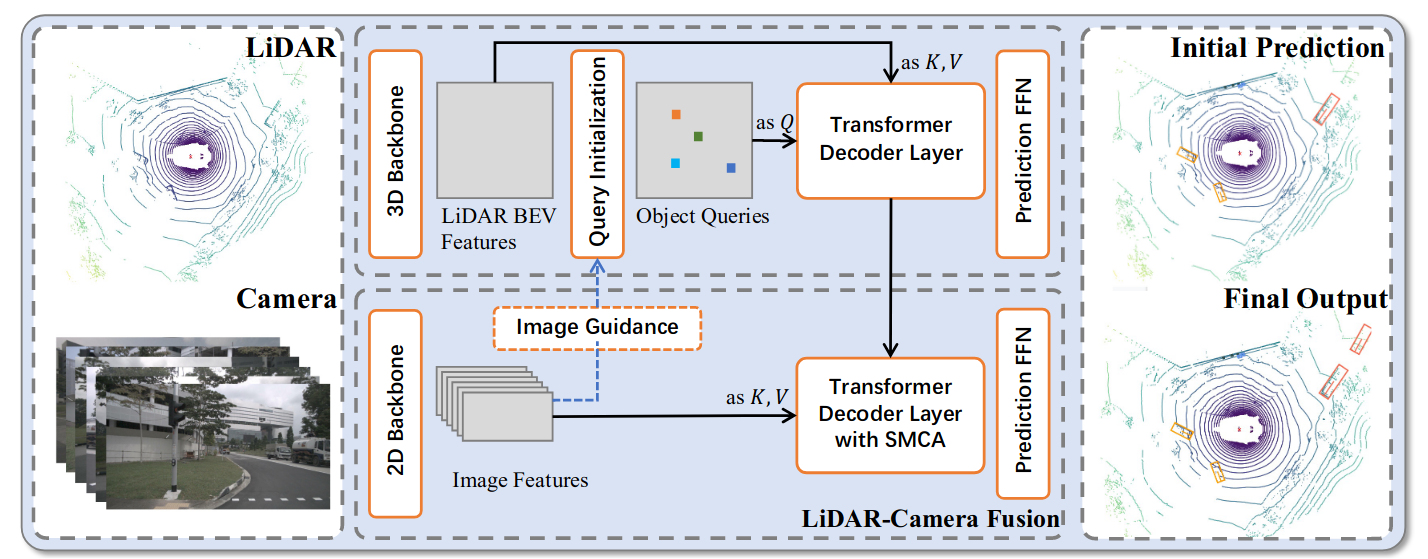
Figure 2. Overall pipeline of TransFusion. Our model relies on standard 3D and 2D backbones to extract LiDAR BEV feature map and image feature map. Our detection head consists of two transformer decoder layers sequentially: (1) The first layer produces initial 3D bounding boxes using a sparse set of object queries, initialized in a input-dependent and category-aware manner. (2) The second layer attentively associates and fuses the object queries (with initial predictions) from the first stage with the image features, producing rich texture and color cues for better detection results. A spatially modulated cross attention (SMCA) mechanism is introduced to involve a locality inductive bias and help the network better attend to the related image regions. We additionally propose an image-guided query initialization strategy to involve image guidance on LiDAR BEV. This strategy helps produce object queries that are difficult to detect in the sparse LiDAR point clouds.
LiDAR-Camera Fusion
Image Feature Fetching.
Although impressive improvement has been brought by point-level fusion methods, their fusion quality is largely limited by the sparsity of LiDAR points. When an object only contains a small number of LiDAR points, it can fetch only the same number of image features, wasting the rich semantic information of high-resolution images. To mitigate this issue, we do not fetch the multiview image features based on the hard association between LiDAR points and image pixels. Instead, we retain all the image features $F_C \in R^{N_v \times H \times W \times d}$ as our memory bank, and use the cross-attention mechanism in the transformer decoder to perform feature fusion in a sparseto-dense and adaptive manner, as shown in Fig. 2.
SMCA for Image Feature Fusion.
To mitigate the sensitivity towards sensor calibration and inferior image features brought by the hard-association strategy, we leverage the cross-attention mechanism to build the soft association between LiDAR and images, enabling the network to adaptively determine where and what information should be taken from the images.
However, as the LiDAR features and image features are from completely different domains, the object queries might attend to visual regions unrelated to the bounding box to be predicted, leading to a long training time for the network to accurately identify the proper regions on images.
Inspired by [1], we design a spatially modulated cross attention (SMCA) module, which weighs the cross attention by a 2D circular Gaussian mask around the projected 2D center of each query. The 2D Gaussian weight mask M is generated in a similar way as CenterNet, $M_{ij} = exp(- \frac{(i-c_x)^2 + (j - c_y)^2}{\sigma r^2}),$ where (i, j) is the spatial indices of the weight mask M, (c_x, c_y) is the 2D center computed by projecting the query prediction onto the image plane, $r$ is the radius of the minimum circumscribed circle of the projected corners of the 3D bounding box, and $\sigma$ is the hyper-parameter to modulate the bandwidth of the Gaussian distribution.
###
Comments
Pros
- Solve the heterogeneity in the Number of Local Updates in Federated Learning
- Proposed a general framework which can guarantee the convergence to the stationary point.
Cons
(need further experiment)
Further work
Extending the theoretical framework to adaptive optimization methods or gossip-based training method.
Comments
(need further experiment)
References
[1] Gao, Peng, et al. “Fast convergence of detr with spatially modulated co-attention.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.




