
Basic Information
Authors: Runsheng Xu, Jinlong Li, Xiaoyu Dong, Hongkai Yu, Jiaqi Ma
Organization: University of California, Los Angeles, UCLA Mobility Lab; Cleveland State University, Cleveland Vision & AI Lab; Northwestern University;
Source: IEEE International Conference on Robotics and Automation (ICRA) 2023
Source Code: None
Content
Motivation
Despite the advancements in Vehicle-to-Everything (V2X) communication intermediate fusion strategy, previous methods conduct experiments under a strong assumption that all agents are equipped with identical neural networks to extract neural features. This overlooks a critical fact: deploying the same model for all agents is unrealistic, especially for connected autonomous driving. For example, as shown in (a) from Fig. 1, the detection models on connected automated vehicles (CAV) and infrastructure products of distinct companies are usually dissimilar.
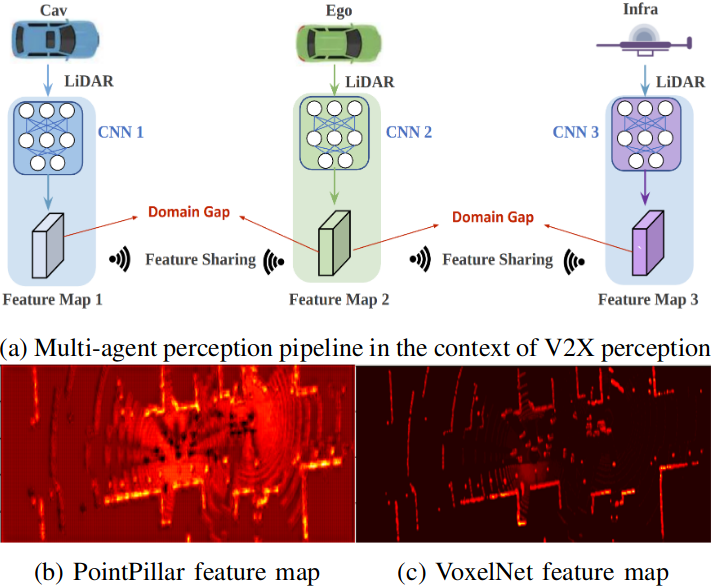
Figure 1. Illustration of domain gap of different feature maps for multi-agent perception.. Here we use V2X cooperative perception in autonomous driving as an example. (a) Ego vehicle receives the shared feature maps from other CAV and infrastructure with different CNN models, which causes domain gaps. (b) Visualization of feature map from ego, which is extracted from PointPillar. (c) Feature map from CAV, which is extracted from VoxelNet. Brighter pixels represent higher feature values.
In general, we can observe the features are dissimilar in three aspects:
- Spatial resolution. Because of the different voxelization parameters, LiDAR cropping range, and downsampling layers, the spatial resolutions are different.
- Channel number. The channel dimensions are distinct due to the difference in convolution layers’ settings.
- Patterns. As Fig. 1 shows, PointPillar and VoxelNet have the opposite patterns: The object positions have relatively low values on the feature map for PointPillar but high values for VoxelNet.
To address the three dominant distinctions, we present the first Multi-agent Perception Domain Adaption framework, dubbed as MPDA, to bridge the domain gap.
Evaluation
Metric: Average Precisions (AP) at Intersection-over-Union (IoU) threshold of 0.7 (AP@0.7).
Evaluation protocols: During training, we randomly select one agent as the ego agent. During testing, we choose a fixed one as the ego for each scenario.
Datasets
V2XSet
Result
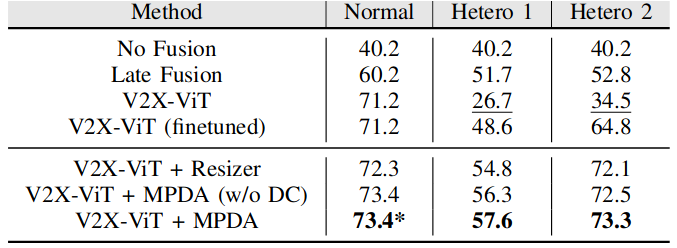
Table 1. 3D detection performance in Normal scenario (w/o domain gap) and Hetero scenarios (w/ domain gap). We show the Average Precision (AP) at IoU=0.7. DC stands for domain classifier. * notes that we do not use the domain classifier when training on the normal scenario.
Method
Fig. 2(a) shows the overall architecture of MPDA, which consists of 1) a learnable feature resizer, 2) a sparse cross-domain transformer, 3) a domain classifier, and 4) multi-agent feature fusion.
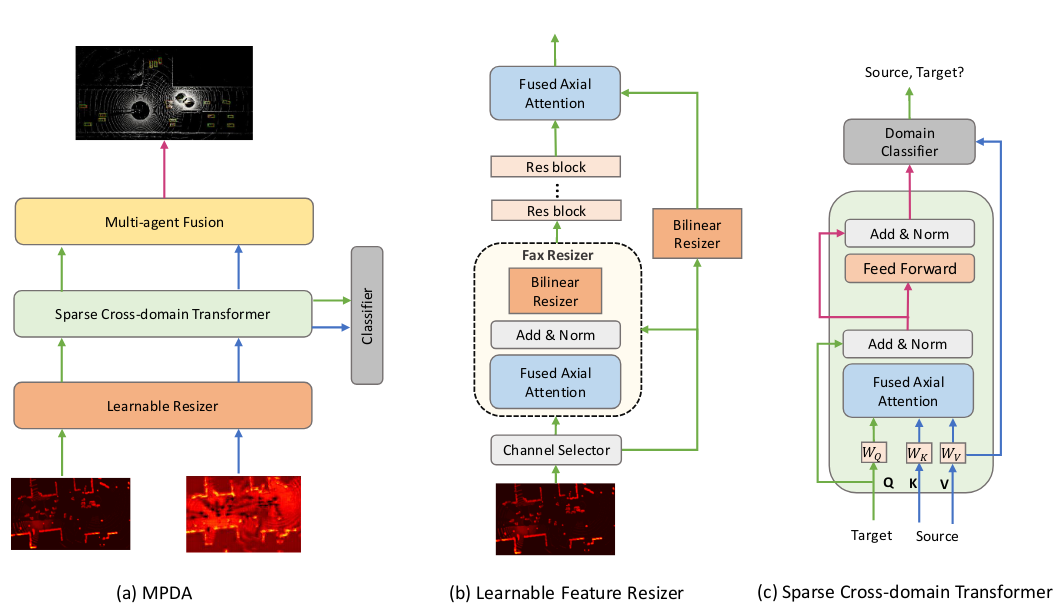
Figure 2. Illustration of domain gap of different feature maps for multi-agent perception.. Here we use V2X cooperative perception in autonomous driving as an example. (a) Ego vehicle receives the shared feature maps from other CAV and infrastructure with different CNN models, which causes domain gaps. (b) Visualization of feature map from ego, which is extracted from PointPillar. (c) Feature map from CAV, which is extracted from VoxelNet. Brighter pixels represent higher feature values.
Learnable Feature Resizer
We regard the feature maps computed locally on ego vehicle as source domain features $F_S \in \mathbb{R}^{1 \times H_S \times W_S \times C_S}$ and received features from other agents as target domain features $F_T \in \mathbb{R}^{N \times H_T \times W_T \times C_T}$, where $N$ is the number of other collaborators/agents,$H$ is the height, $W$ is the width, $C$ is the channel number. The goal of feature resizer $\Phi$ is to align the dimensions of the source domain feature with the target domain in a learnable way:
\[F'_T = \Phi(F_T), s.t. F'_T \in \mathbb{R}^{1 \times H_S \times W_S \times C_S}.\]The architecture of our learnable feature resizer is designed as Fig. 2(b) shows, which includes four major components: channel aligner, FAX resizer, skip connection, and res-block.
Channel Aligner
We use a simple $1 \times 1$ convolution layer to align the channel dimension, whose input channel number is $C_{in} = 2C_S$ and outputs $C_S$ channels. When $C_T < C_{in}$, we perform padding with randomly selected channels from $F_T$ to meet the required input channel number for the $1 \times 1$ convolution.
FAX Resizer
Since LiDAR features are usually sparse due to empty voxels, applying large-kernel convolution to get global information may diffuse the meaningless information to the important area. Therefore, we apply the fused axial (FAX) attention block [1] before bilinear resizing to fetch better feature representations. FAX sparsely employs local window and grid attention to efficiently capture global and local interactions. More importantly, it can discard empty voxels through a dynamic attention mechanism to eliminate their potential negative effects. After FAX, a bilinear resizer is implemented to reshape the feature map to the same spatial dimension as the source feature map. Compared to simple bilinear interpolation, our FAX resizer can adjust the input features first to avoid misalignment and distortion issues during resizing.
Res-Block
We implement standard residual blocks [2] $r$ times after resizing the feature maps to further refine them.
Sparse Cross-Domain Transformer
fter retrieving the resized feature $F’_T$ , we need to convert its pattern to be indistinguishable from the domain classifier to obtain the domain-invariant features. To reach this goal, we need to effectively reason the correlations between $F’_T$ and $F_S$ both locally and globally. Fig. 2(c) shows the details of our proposed architecture. It can be referred in [3].
Multi-Agent Fusion
Our MPDA framework is very flexible and can integrate most of the multi-agent fusion algorithms. In this work, we select a state-of-the-art model, V2X-ViT [4], as our multiagent fusion algorithm.
Loss
For 3D object detection, we use the smooth L1 loss for bounding box regression and focal loss for classification. For the domain classifier, we utilize cross-entropy loss to learn domain-invariant features. The final loss is the combination of detection and domain adaptation loss:
\[L = \alpha L_{det} + \beta L_{domain}\]Comments
Pros
- mitigate the domain gap in connected vehicle communicatation.
Cons
- resizer can be improved (needed further experiments)
Further work
- attack deffense
- robust
Comments
(needed further experiments)
References
[1] R. Xu, Z. Tu, H. Xiang, W. Shao, B. Zhou, and J. Ma, “Cobevt: Cooperative bird’s eye view semantic segmentation with sparse transformers,” arXiv preprint arXiv:2207.02202, 2022.
[2] H. Talebi and P. Milanfar, “Learning to resize images for computer vision tasks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 497–506.
[3] T. Xu, W. Chen, W. Pichao, F. Wang, H. Li, and R. Jin, “Cdtrans: Cross-domain transformer for unsupervised domain adaptation,” in International Conference on Learning Representations, 2021.
[4] R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,” in Proceedings of the European Conference on Computer Vision (ECCV), 2022.




