
Basic Information
Authors: Zeyu Yang, Jiaqi Chen, Zhenwei Miao, Wei Li, Xiatian Zhu, Li Zhang
Organization: Fudan University, Alibaba DAMO Academy, NTU, University of Surrey
Source: Advances in Neural Information Processing Systems 2022
Source Code: https://github.com/fudan-zvg/DeepInteraction
Content
Motivation
Existing multi-modal 3D objection detection methods typically adopt a modality fusion strategy (Figure 1(a)) by combining individual per-modality representations into a single hybrid representation.
This fusion approach is, however, structurally restricted due to its intrinsic limitation of potentially dropping off a large fraction of modality-specific representational strengths due to largely imperfect information fusion into a unified representation.
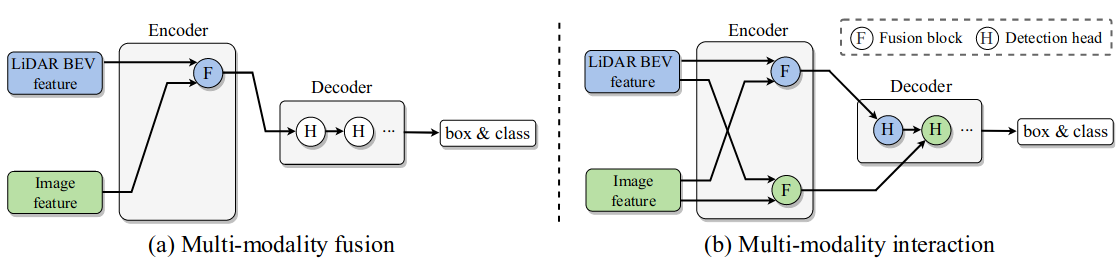
Figure 1. Schematic strategy comparison. (a) Existing multi-modality fusion based 3D detection: Fusing individual per-modality representations into a single hybrid representation and from which the detection results are further decoded. (b) Our multi-modality interaction based 3D detection: Maintaining two modality-specific representations throughout the whole pipeline with both representational interaction in the encoder and predictive interaction in the decoder.
To overcome the aforementioned limitations, in this work a novel modality interaction strategy (Figure 1(b)) for multi-modal 3D object detection is introduced. Our key idea is that, instead of deriving a fused single representation, we learn and maintain two modality-specific representations throughout to enable inter-modality interaction so that both information exchange and modalityspecific strengths can be achieved spontaneously.
The key insight behind our approach is that we maintain two modality-specific feature representations and conduct representational and predictive interaction for maximally exploring their complementary benefits whilst preserving their respective strengths.
Evaluation
Metric: Mean average precision (mAP) and nuScenes detection score (NDS) are used as the evaluation metric of 3D detection performance. The final mAP is computed by averaging over the distance thresholds of 0.5m, 1m, 2m, 4m across 10 classes. NDS is a weighted average of mAP and other attribute metrics, including translation, scale, orientation, velocity, and other box attributes.
Implementation details: Our implementation is based on the public code base mmdetection3d. For the image branch backbone, we use a simple ResNet-50 and initialize it from the instance segmentation model Cascade Mask R-CNN pretrained on COCO and then nuImage, which is same as Transfusion. To save the computation cost, we rescale the input image to 1/2 of its original size before feeding into the network, and freeze the weights of image branch during training.
Datasets
nuScenes dataset
Result
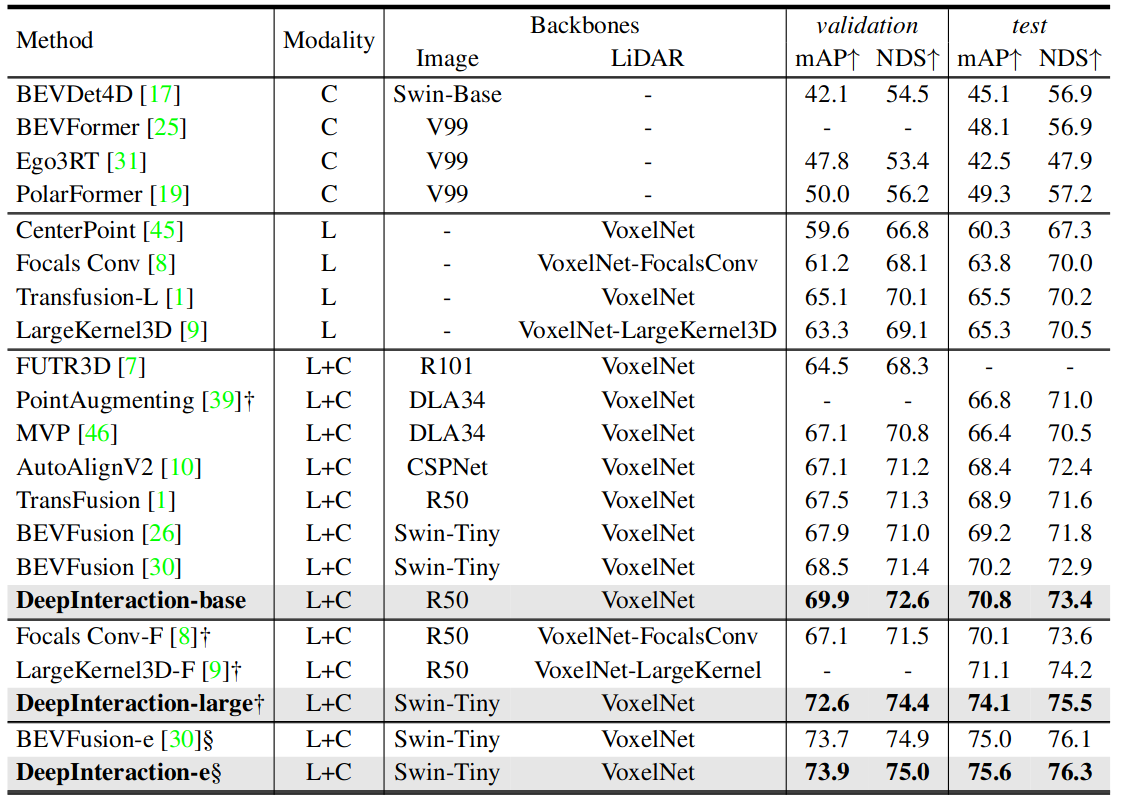
Table 1. Comparison with state-of-the-art methods on the nuScenes test set. Metrics: mAP(%), NDS(%). ‘L’ and ‘C’ represent LiDAR and camera, respectively. † denotes test-time augmentation is used. § denotes that test-time augmentation and model ensemble both are applied for testing.
Method
We present a novel modality interaction framework, dubbed DeepInteraction, for multi-modal (3D point clouds and 2D multi-camera images) 3D object detection. In contrast to all prior arts, we learn two representations specific for 3D LiDAR and 2D image modalities respectively, whilst conducting multi-modal interaction through both model encoding and decoding. An overview of DeepInteraction is shown in Figure 1(b). It consists of two main components: An encoder with multi-modal representational interaction, and a decoder with multi-modal predictive interaction.
Encoder: Multi-modal representational interaction
Our encoder is formulated as a multiinput-multi-output (MIMO) structure: Taking as input two modality-specific scene representations which are independently extracted by LiDAR and image backbones, and producing two refined representations as output. Overall, it is composed by stacking multiple encoder layers each with (1) multi-modal representational interaction (MMRI), (2) intra-modal representational learning (IML), and (3) representational integration.
multi-modal representational interaction (MMRI)
Each encoder layer takes the representations of two modalities, i.e., the image perspective representation $h_c$ and the LiDAR BEV representation $h_p$, as input. Our multi-modal representational interaction aims to exchange the neighboring context in a bilateral cross-modal manner, as shown in Figure 2.
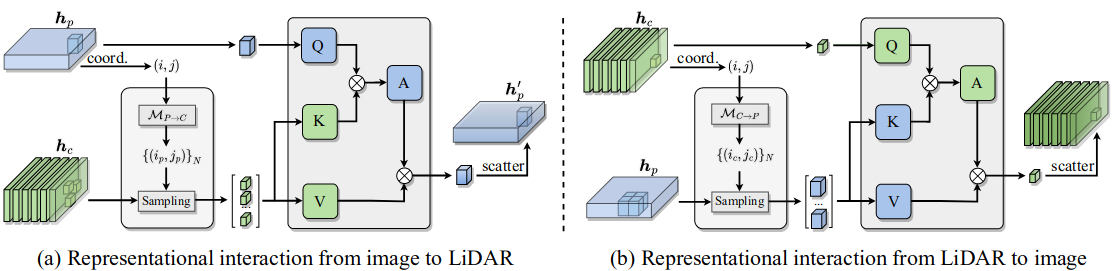
Figure 2. Illustration of the multi-modal representational interactions. Given two modality-specific representations, the image-to-LiDAR feature interaction (a) spread the visual signal in the image representation to the LiDAR BEV representation, and the LiDAR-to-image feature interaction (b) takes cross-modal relative contexts from LiDAR representation to enhance the image representations.
It consists of two steps: 1) Cross-modal correspondence mapping and sampling. build the pixel-to-pixel(s) correspondence between the representations $h_p$ and $h_c$. dense mappings between the image coordinate frame $c$ and the BEV coordinate frame $p$ ($M_{p \rightarrow c}$ and $M_{c \rightarrow p}$).
2) Attention-based feature interaction. For an image feature point as query $q = h_c^{[i_c, j_c]}$, its crossmodality neighbors $N_q$ are used as the key $k$ and value $v$ for cross-attention learning.
\[f_{\phi_{c \rightarrow p}}(h_c, h_p)^{[i, j]} = \sum_{k, v \in N_q} softmax(\frac{qk}{\sqrt{d}})v, \tag1\label1\]where $h[i,j]$ denotes indexing the element at location $(i, j)$ on the 2D representation $h$. This is image-to-LiDAR representational interaction.
The other way around, given a LiDAR BEV feature point as query $q$ , we similarly obtain its cross-modality neighbors
3) Intra-modal representational learning. Concurrently, we conduct intra-modal representational learning complementary to multi-modal interaction. The same local attention \eqref{1} is consistently applied. For either modality, we use a $K \times K$ grid neighborhood as the key and value.
4) Representational integration. Each layer ends up by integrating the two outputs per modality,
\[h'_p = FFN(Concat(FFN(Concat(h_p^{p \rightarrow p}, h_p^{c \rightarrow p}), h_p))),\] \[h'_c = FFN(Concat(FFN(Concat(h_p^{c \rightarrow c}, h_c^{p \rightarrow c}), h_c))),\]where FFN specifies a feed-forward network, and Concat denotes element-wise concatenation.
Decoder: Multi-modal predictive interaction
Beyond considering the multi-modal interaction at the representation-level, we further introduce a decoder with multi-modal predictive interaction (MMPI) to maximize the complementary effects in prediction. As depicted in Figure 3(a), our core idea is to enhance the 3D object detection of one modality conditioned on the other modality. In particular, the decoder is built by stacking multiple multi-modal predictive interaction layers, within which predictive interactions are formulated in an alternative and progressive manner.
Similar to the decoder of DETR, we cast the 3D object detection as a set prediction problem. Here, we define a set of $N$ object queries $\lbrace Q_n \rbrace _{n=1}^N$ and the resulting $N$ object predictions $\lbrace b_n, c_n \rbrace _{n=1}^N$, where $b_n$ and $c_n$ denote the predicted bounding box and category for the $n$-th prediction.
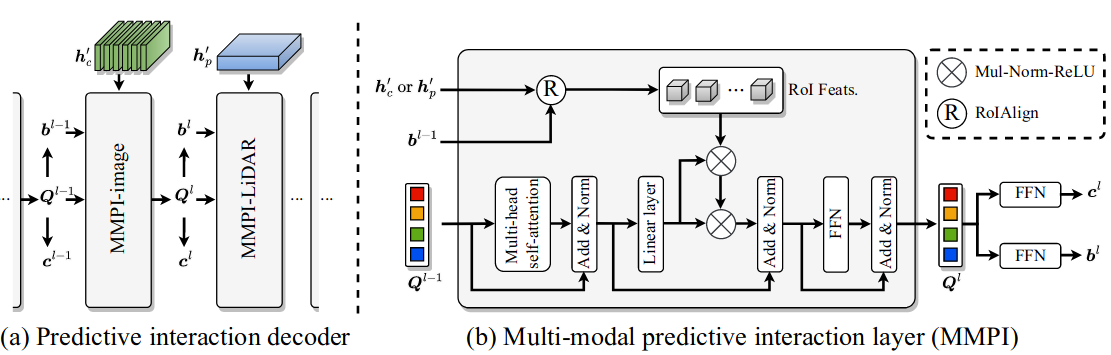
Figure 3. Illustration of our multi-modal predictive interaction. Our predictive interaction decoder (a) generates predictions via (b) progressively interacting with two modality-specific representations.
Multi-modal predictive interaction layer (MMPI)
For the $l$-th decoding layer, the set prediction is computed by taking the object queries $\lbrace Q_n^{(l-1)} \rbrace^N_{n=1}$ and the bounding box predictions $\lbrace b_n^{(l-1)} \rbrace^N_{n=1}$ from previous layer as inputs and enabling interaction with the intensified image $h’_p$ or LiDAR $h’_c$We formulate the multi-modal predictive interaction layer (Figure 3(b)) for specific modality as follows:
Multi-modal predictive interaction on image representation (MMPI-image)
Taking as input 3D object proposals $\lbrace b_n^{(l-1)} \rbrace^N_{n=1}$ and object queries $\lbrace Q_n^{(l-1)} \rbrace^N_{n=1}$ generated by the previous layer, this layer leverages the image representation $h_c′$ for further prediction refinement. To integrate the previous predictions $\lbrace b_n^{(l-1)} \rbrace^N_{n=1}$ , we first extract N Region of Interest (RoI) features $\lbrace R_n \rbrace^N_{n=1}$ from the image representation $h_c′$, is the extracted RoI feature for the $n$-th query, ($S \times S$) is RoI size, and $C$ is the number of channels of RoI features. Specifically, for each 3D bounding box, we project it onto image representation $h_c’$ to get the 2D convex polygon and take the minimum axis-aligned circumscribed rectangle. The resulted interactive representation is further used to obtain the updated object query $\lbrace Q_n^{l} \rbrace^N_{n=1}$
Multi-modal predictive interaction on LiDAR representation (MMPI-LiDAR)
This layer shares the same design as the above except that it takes as input LiDAR representation instead. With regards to the RoI for LiDAR representation, we project the 3D bounding boxes from previous layer to the LiDAR BEV representation $h’_p$ and take the minimum axis-aligned rectangle.
Comments
Pros
- Solve the heterogeneity in the Number of Local Updates in Federated Learning
- Proposed a general framework which can guarantee the convergence to the stationary point.
Cons
(need further experiment)
Further work
Extending the theoretical framework to adaptive optimization methods or gossip-based training method.
Comments
(need further experiment)




