
Basic Information
Authors: Jiaxun Cui, Hang Qiu, Dian Chen, Peter Stone, Yuke Zhu
Organization: The University of Texas at Austin, Stanford University, Sony AI
Source: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
Source Code: https://ut-austin-rpl.github.io/Coopernaut/
Content
Motivation
Recent work on cooperative driving has demonstrated the benefit of cross-vehicle perception for augmenting sensing capabilities and driving decisions. Nonetheless, these methods have abstracted away raw sensory data with lowdimensional meta-data.Prior work introduced 3D sensor fusion (AVR, Cooper) and representation fusion (V2VNet) algorithms that aggregate perception results from nearby vehicles via V2V channels. They focused on 3D detection and motion forecasting on static datasets, rather than interactive driving policies.
We introduce COOPERNAUT, an end-to-end cooperative driving model for networked vehicles. COOPERNAUT learns to fuse encoded LiDAR information shared by nearby vehicles under realistic V2V channel capacity. To communicate meaningful scene information from nearby vehicles while conforming to bandwidth limits, we design our driving policy architecture based on the Point Transformer, a self-attention network for point cloud processing.
Recent work proposed multi-agent perception models to process sensor information and share compact representations within a local traffic network. In contrast, we focus on cooperative driving of networked vehicles with onboard visual data and realistic networking conditions, advancing towards real-world V2V settings.
Evaluation
**Metric: ** We report three metrics, Success Rate, Collision Rate, and Success weighted by Completion Time:
- Success Rate (SR). A successful completion of the scenario is defined as the ego agent reaching a designated target location in a permissible time without collision or prolonged stagnation. The success rate is defined as the percentage of successful completions among all evaluated traces.
- Collision Rate (CR). Collision is the most common failure mode. Collision rate is defined as the percentage of evaluation traces where the ego vehicle collides with any entity, such as vehicles, buildings, etc.
- Success weighted by Completion Time (SCT). SR reflects overall task success or failure. It does not differentiate the amount of time a driving agent needs to complete the traces. We introduce a third metric to weigh the success rate by the completion time ratio between the expert and the agent.
Datasets
Self-built datasets: AUTOCASTSIM, a simulation framework which offers network-augmented autonomous driving simulation on top of CARLA.
Result

Table 1. Quantitative results of different models over three repeated runs. SR: Success Rate, in percentage; SCT: Success weighted by Completion Time, in percentage; CR: Collision Rate, in percentage; In the Bandwidth column, we report the communication throughput required without data compression. The bandwidth is calculated by assuming 10 Hz LiDAR scanning frequency.
Methods
Problem Statement
Our goal is to learn a closed-loop policy that controls an autonomous ego vehicle, which receives LiDAR observations $O_t^{(ego)}$ at time $t$. Assume that there exist a variable number of $N_t$ neighboring vehicles in the range of V2V communications at time $t$, where $O_t^{(i)}$ is the raw 3D point cloud from the onboard LiDAR of the $i$-th vehicle. The cooperative driving policy for the ego vehicle is to find a policy $\pi(a_t|O_{t}^{(ego)}, O_{t}^{(1)}, \dots, O_{t}^{(N_t)})$ that makes control decisions at based on the joint observations of the ego vehicle and the $N_t$ neighboring vehicles.
Background: Point Transformer
Backbone is the Point Transformer [1], a newly-developed neural network structure that learns compact point-based representations from 3D point clouds. It reasons about non-local interactions among points and produces permutation-invariant representations, making itself effective in aggregating multi-vehicle point clouds. Here we provide a brief review of Point Transformers.
We adopt the same design as Zhao et al. [1], which uses vector self-attention to construct the Point Transformer Layer. We also apply subtraction between features and append a position encoding function $\delta$ to both the attention vector $\gamma$ and the transformed features $\alpha$:
\[y_i = \sum_{x_j \in X(i)} \rho(\gamma(\phi(x_i) - \psi(x_j) + \delta)) \odot ( \alpha(x_j) + \delta),\]Here the $x_i$ and $x_j$ are input features of the point $i$ and $j$ respectively, $y_i$ is the output attention feature for point $i$, and $X(i)$ represents the set of points in the neighborhood of $x_i$; $\phi$, $\psi$ and $\alpha$ are point-wise feature transformations, an MLP; $\gamma$ is an MLP mapping function with two layers and one ReLU non-linearity; $\delta$ is a position-encoding function and $\rho$ is a normalization function softmax. Position encoding function is get by:
\[\delta = \theta(p_i - p_j),\]where $\theta$ is an MLP with two linear layers and one ReLU. A Point Transformer block is shown in Figure 1, which integrates the self-attention layer, linear projections, and a residual connection.
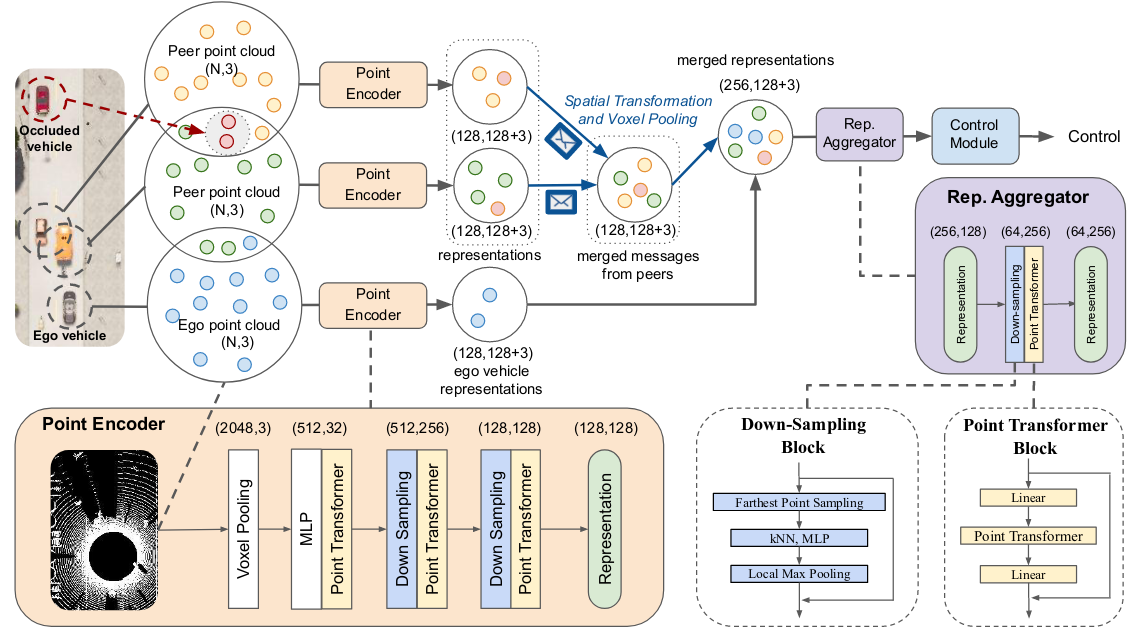
Figure 1. COOPERNAUT is an end-to-end vision-based driving model for networked vehicles. It contains a Point Encoder to extract critical information locally for sharing, a Representation Aggregator for merging multi-vehicle messages, and a Control Module to reason about the joint messages. Each message produced by the encoder has 128 keypoint coordinates and their associated features. The message is then spatially transformed into the ego frame. The ego vehicle merges incoming messages and compute aggregated representations through voxel max-pooling. Finally, the aggregator synthesizes joint representations from the ego vehicle and all its neighbors before passing them to the Control Module to produce control decisions. The numbers in parentheses denote data dimensions.
COOPERNAUT model
COOPERNAUT model, illustrated in Figure 2, is composed of a Point Encoder for each neighboring V2V vehicle to encode its sensory data into compact messages, a Representation Aggregator to integrate the messages from neighboring cars with the ego perception, and a Control Module which translates the integrated representations to driving commands. The key challenge is to transmit sensory information efficiently through realistic V2V channels, understand the traffic situation from the aggregated information, and determine the reactive driving action in real-time.
Point Encoder
To reduce communication burdens, every V2V vehicle processes its own LiDAR data locally and encodes the raw 3D point clouds into keypoints, each associated with a compact representation learned by the Point Transformer blocks. In our experiments, we preprocess 65,536 raw LiDAR points to 2,048 points via voxel pooling, i.e., representing the points in a voxel grid using their voxel centroid.
The message $M_j$ produced by the $j$-th vehicle comprises a set of position-based representations $M_j$ and is mathematically described as $M_j = {(p_{jk}, R_{p_{jk}} )}^K$, where $p_{jk} \in R^3$ for $k = 1, \dots, K$ is the position of a keypoint in 3D space and $R_{p_{jk}}$ is its corresponding feature vector produced by the Point Encoder. We limit the size of $M_j$ to be at most $K$ tuples.
Representation Aggregator
Messages transmitted from other vehicles need to be fused and interpreted by the ego vehicle. The Representation Aggregator (RA) for cooperative perception is implemented as a voxel max-pooling operation and a point transformer block. RA first spatially transforms the keypoints in other vehicles’ coordinates to the ego vehicle’s frame using their relative poses. This operation assumes accurate vehicle localization (e.g., using HD maps). Finally, it fuses the multi-view perception information with another Point Transformer block. The two operations above preserve the permutation invariance with respect to the ordering of other vehicles and can handle a variable number of sharing vehicles.
Control Module
The control module is a fully-connected neural network designed to make control decisions based on the received messages. These control decisions include the throttle, brake, and steering, denoted as scalar T, B, S respectively.
Policy Learning
(TODO)
Comments
Pros
- Use a new backbone, point transformer.
- Information is interesting and make sense
Cons
- It should include more related work
- I suspect transforming raw data after down-sampling may be more efficient and perform better?
Further work
maybe not all point will be selected and sent to ego-vehicle
Comments
(need further experiment)
References
[1] Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip H.S. Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16259–16268, October 2021. 2, 3




