
Basic Information
Authors: Tingting Liang, Hongwei Xie, Kaicheng Yu, Zhongyu Xia, Zhiwei Lin, Yongtao Wang, Tao Tang, Bing Wang, Zhi Tang
Organization: Wangxuan Institute of Computer Technology; DAMO Academy, Alibaba Group; Shenzhen Campus of Sun Yat-sen University
Source: Advances in Neural Information Processing Systems 2022
Source Code: https://github.com/ADLab-AutoDrive/BEVFusion
Content
Motivation
People discover that bird’s eye view (BEV) has been an de-facto standard for autonomous driving scenarios as, generally speaking, car cannot fly.
Recently, people have designed LiDAR-camera fusion deep networks to better leverage information from both modalities. Specifically, the majority of works can be summarized as follow: i) given one or a few points of the LiDAR point cloud, LiDAR to world transformation matrix and the essential matrix (camera to world); ii) people transform the LiDAR points or proposals into camera world and use them as queries, to select corresponding image features. This line of work constitutes the state-of-the-art methods of 3D BEV perception.
However, one underlying assumption that people overlooked is, that as one needs to generate image queries from LiDAR points, the current LiDAR-camera fusion methods intrinsically depend on the raw point cloud of the LiDAR sensor, as shown in Fig. 1. In the realistic world, people discover that if the LiDAR sensor input is missing, for example, LiDAR points reflection rate is low due to object texture, a system glitch of internal data transfer, or even the field of view of the LiDAR sensor cannot reach 360 degrees due to hardware limitations[1], current fusion methods fail to produce meaningful results.
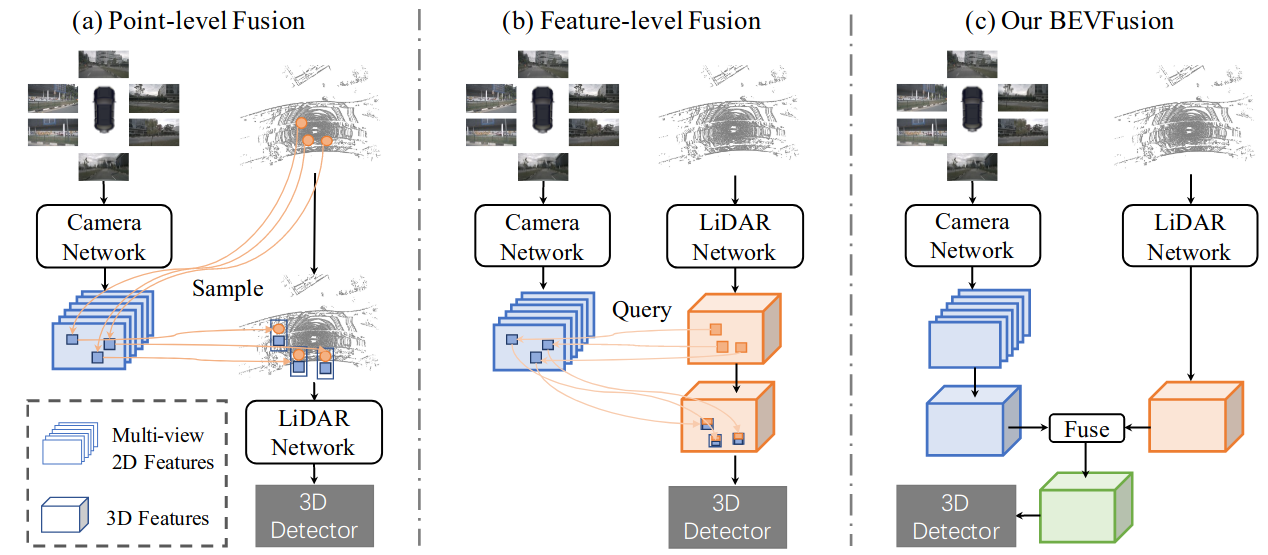
Figure 1. Comparison of our framework with previous LiDAR-camera fusion methods. Previous fusion methods can be broadly categorized into (a) point-level fusion mechanism that project image features onto raw point clouds, and (b) feature-level fusion mechanism that projects LiDAR feature or proposals on each view image separately to extract RGB information. (c) In contrast, we propose a novel yet surprisingly simple framework that disentangles the camera network from LiDAR inputs.
We argue the ideal framework for LiDAR-camera fusion should be, that each model for a single modality should not fail regardless of the existence of the other modality, yet having both modalities will further boost the perception accuracy.
Evaluation
Metric. We use nuScenes detection score (NDS) and mean average precision (mAP) as evaluation metrics.
Implementation details. We conduct BEVFusion with Dual-Swin-Tiny as 2D bakbone for image-view encoder. PointPillars, CenterPoint, and TransFusion-L are chosen as our LiDAR stream and 3D detection head.
Datasets
large-scale autonomous-driving dataset for 3D detection, nuScenes. Each frame contains six cameras with surrounding views and one point cloud from LiDAR.
Result
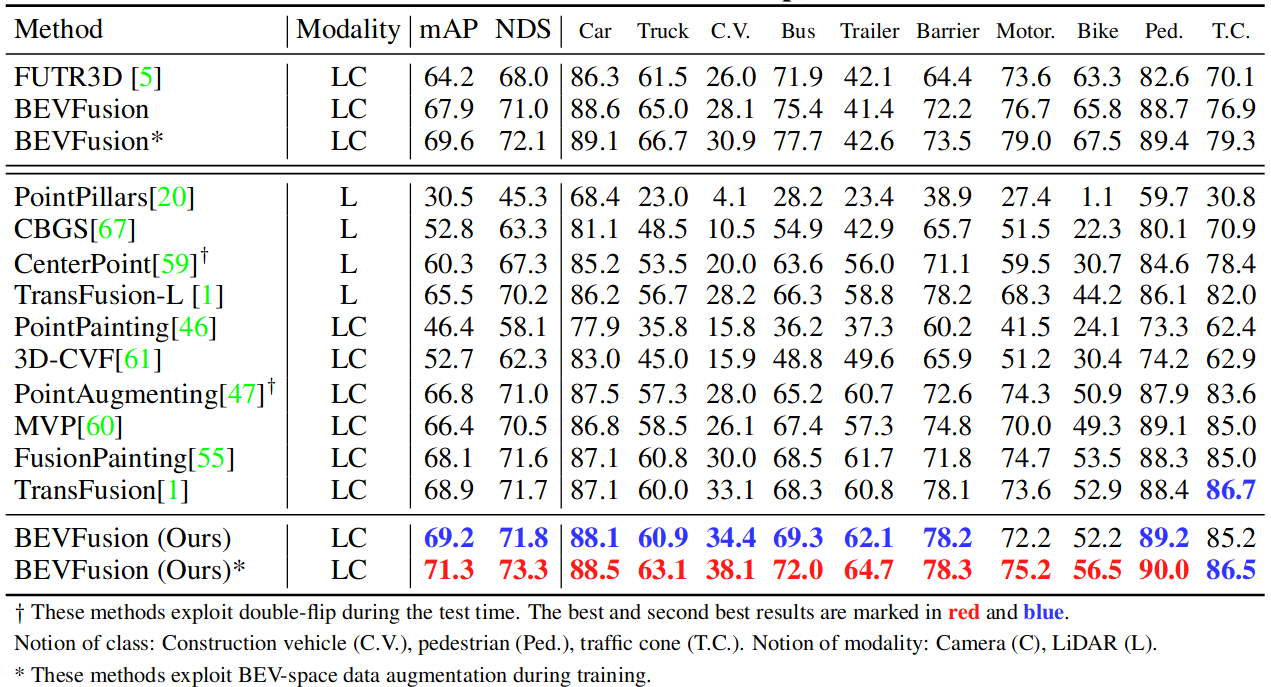
Table 1. Results on the nuScenes validation (top) and test (bottom) set.
Method
As shown in Fig. 2, we present our proposed framework, BEVFusion, for the 3D object detection in detail.
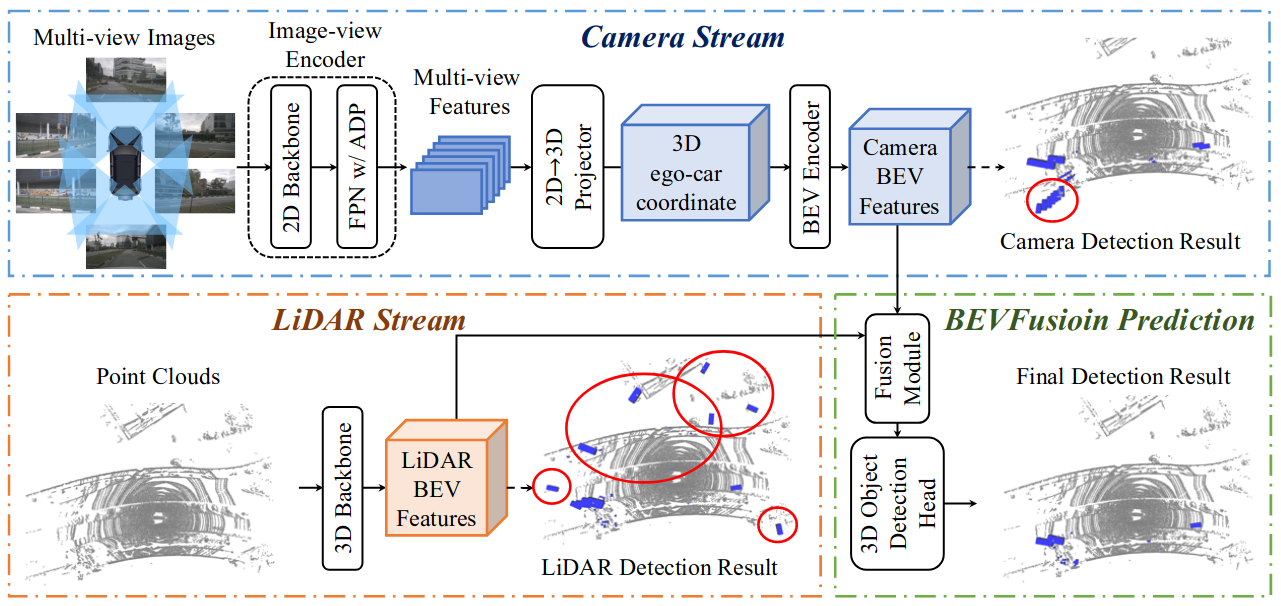
Figure 2. An overview of BEVFusion framework. With point clouds and multi-view image inputs, two streams separately extract features and transform them into the same BEV space: i) the cameraview features are projected to the 3D ego-car coordinate features to generate camera BEV feature; ii) 3D backbone extracts LiDAR BEV features from point clouds. Then, a fusion module integrates the BEV features from two modalities. Finally, a task-specific head is built upon the fused BEV feature and predicts the target values of 3D objects. In detection result figures, blue boxes are predicted bounding boxes, while red circled ones are the false positive predictions.
Camera stream architecture: From multi-view images to BEV space
Image-view Encoder
Image-view Encoder aims to encode the input images into semantic information-rich deep features. It consists of a 2D backbone for basic feature extraction and a neck module for scale variate object representation. we use the more representative one, Dual-Swin-Tiny as the backbone. we use a standard Feature Pyramid Network (FPN) on top of the backbone to exploit the features from multi-scale resolutions. To better align these features, we first propose a simple feature Adaptive Module (ADP) to refine the upsampled features. Specifically, we apply an adaptive average pooling and a 1 × 1 convolution for each upsampled feature before concatenating.
View Projector Module
As the image features are still in 2D image coordinate, we design a view projector module to transform them into 3D ego-car coordinate. We apply 2D → 3D view projection proposed in [2] to construct the Camera BEV feature. The adopted view projector takes the imageview feature as input and densely predicts the depth through a classification manner.
BEV Encoder Module.
To further encode the voxel feature $V \in R^{X\times Y \times Z \times C}$ into the BEV space feature ($F_{Camera} \in R^ {X\times Y \times C_{Camera}}$ ), we design a simple encoder module. Instead of applying pooling operation or stacking 3D convolutions with stride 2 to compress z dimension, we adopt the Spatial to Channel (S2C) operation to transform V from 4D tensor to 3D tensor $V \in R^{X\times Y \times (ZC)}$ via reshaping to preserve semantic information and reduce cost.
LiDAR stream architecture: From point clouds to BEV space
Similarly, our framework can incorporate any network that transforms LiDAR points into BEV features, $F_{LiDAR} \in R^{X \times Y \times C_{LiDAR}}$. In practice, we adopt three popular methods, PointPillars, CenterPoint and TransFusion as our LiDAR stream to showcase the generalization ability of our framework.
Dynamic fusion module
To effectively fuse the BEV features from both camera ($F_{Camera} \in R^ {X\times Y \times C_{Camera}}$) and LiDAR ($F_{LiDAR} \in R^{X \times Y \times C_{LiDAR}}$) sensors, we propose a dynamic fusion module in Fig. 3.
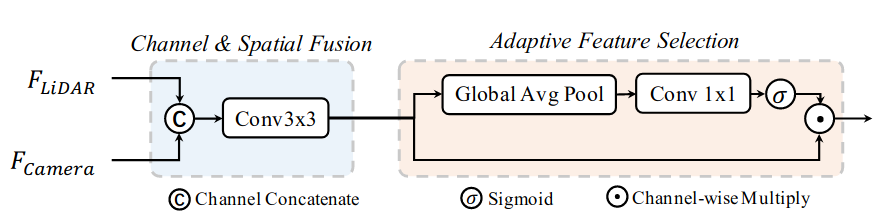
Figure 3. Dynamic Fusion Module.
Given two features under the same space dimension, an intuitive idea is to concatenate them and fuse them with learnable static weights. Inspired by Squeeze-and-Excitation mechanism, we apply a simple channel attention module to select important fused features. Our fusion module can be formulated as:
\[F_{fuse} = f_{adaptive}(f_{static}([F_{camera}, F_{LiDAR}]))\]where $[\cdot, \cdot]$ denotes the concatenation operation along the channel dimension. $f_{adaptive}$ is formulated as: $f_{adaptive}(F) = \sigma(Wf_{avg}(F))\cdot F$
Detection head
As the final feature of our framework is in BEV space, we can leverage the popular detection head modules from earlier works. This is further evidence of the generalization ability of our framework.
Comments
Pros
- Camera can be used independently
Cons
- The performance decrease seriously when LiDAR data is missing
- The fusion do not consider the domain gap, they just simply do a avg
- The fusion do not condider the attention relation
- some part are over calulation
Further work
Extending the theoretical framework to adaptive optimization methods or gossip-based training method.
Comments
(need further experiment)
References
[1] Kaicheng Yu, Tang Tao, Hongwei Xie, Zhiwei Lin, Zhongwei Wu, Zhongyu Xia, Tingting Liang, Haiyang Sun, Jiong Deng, Dayang Hao, et al. Benchmarking the robustness of lidar-camera fusion for 3d object detection. arXiv preprint arXiv:2205.14951, 2022.
[2] Jonah Philion and S. Fidler. Lift, Splat, Shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In European Conference on Computer Vision (ECCV), 2020.




