
Basic Information
Authors Qi Chen, Xu Ma, Sihai Tang, Jingda Guo, Qing Yang, Song Fu
Organization University of North Texas
Source Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, 2019
Source Code https://github.com/Aug583/F-COOPER
Content
Motivation
- Sensors are just another component of the vehicle that is susceptible to failure.
- Sensors are also limited by their physical capabilities such as scan frequency, range, and resolution.
- Perception gets even worse when sensors are occluded
- Related works main focus is on improving the individual vehicle’s precision, overlooking benefits from cooperative perception. Potential issues involved in cooperative perception, such as accuracy of local perception results, impact on networks, format of data to be exchanged, and data fusion on edge servers, are not addressed.
- It is challenging to send the huge amount of LiDAR data generated by autonomous vehicles in real time.
- We argue that the capacity of feature maps is not fully explored, especially for 3D LiDAR data generated on autonomous vehicles, as the feature maps are used for object detection only by single vehicles.
Therefore, the authors introduce a feature based cooperative perception (FCooper) framework that realizes an end-to-end 3D object detection leveraging feature-level fusion to improve detection precision.
Evaluation
Dataset
- KITTI, a dataset contains labeled data that allows for autonomous vehicles to train detection models and evaluate detection precision. This paper use the 3D Velodyne point cloud data provided by the KITTI dataset.
- Self-made dataset, two car with necessary sensors, such as LiDARs (Velodyne VLP-16), cameras (Allied Vision Mako G-319C), radars (Delphi ESR 2.5), IMU&GPSes (Xsens MTi-G-710 kit),
Test Scenarios
Road intersections, Multi-lane roads, and Campus parking lots.
Baseline
(1)Non-fusion, (2)F-Cooper with VFF, (3) F-Cooper with SFF, (4) raw point clouds fusion method - Cooper
Metrics
Average precision, Intersection over Union (IoU) threshold at 0.7
Result
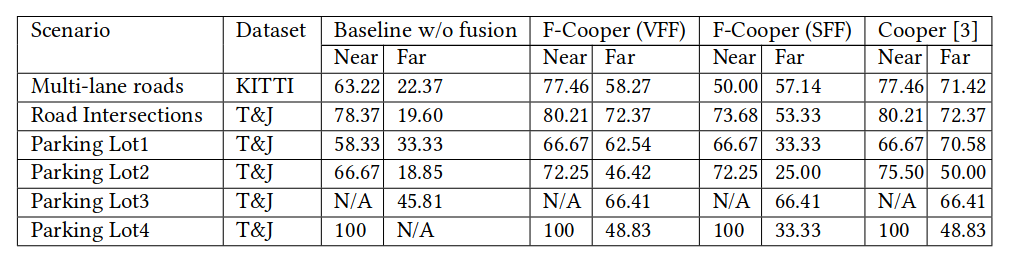
Table 1: Precision comparison between F-Copper and Cooper on Car 1: Average precision (in %). "N/A" means no vehicle exits in the corresponding scenarios. The “Near” and “Far” cut off is 20 meters from the car as the center.
Method
In F-Cooper, we present two schemes for feature fusion: Voxel Feature Fusion (VFF) and Spatial Feature Fusion (SFF).
The first scheme directly fuses the feature maps generated by the Voxel Feature Encoding (VFE) layer, while the second scheme fuses the output spatial feature maps generated by the Feature Learning Network (FLN) [37]. SFF can be viewed as an enhanced version of VFE, i.e., SFF extracts spatial features locally from voxel features available on individual vehicles before they are transmitted into the network.
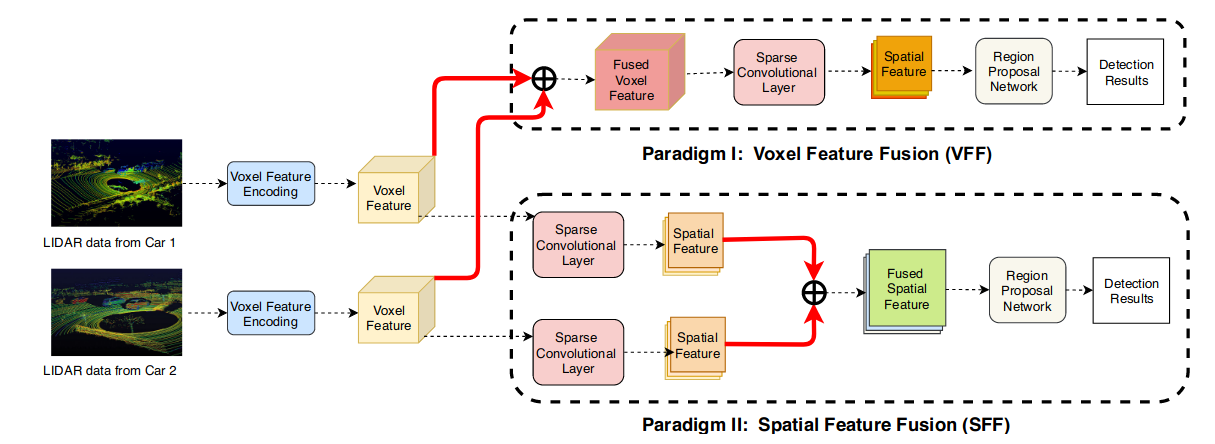
Figure 3: Architecture of the feature based cooperative perception (F-Cooper). F-Cooper has multiple vehicles’ (using two here for illustration) LiDAR data inputs which are processed by the VFE layers respectively to generate voxel features. To fuse 3D features from two cars, two fusion paradigms are designed: voxel features fusion and spatial features fusion. In Paradigm I, two sets of voxel features are fused first and then spatial feature maps are generated. In Paradigm II, spatial features are first obtained locally on individual vehicles and then fused together to generate the ultimate feature maps. Symbol É indicates where the fusion takes place in each paradigm. An RPN is employed for object detection on the ultimate feature maps in both paradigms. We use dashed arrows to denote data flow and bold red lines to present fusion connections. Best viewed in color.
Voxel Features Fusion
A voxel feature map example is shown in Figure 2. For any voxel containing at least one point, a voxel feature can be generated by the VFE layer of VoxelNet.
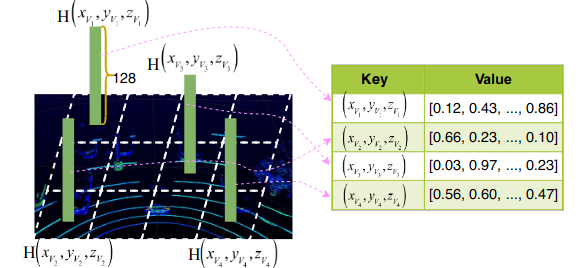
Figure 2. A 128-dimensional feature is generated for each non-empty voxel in LiDAR data.
As shown in Figure 3, of these voxels,a vast majority of empty voxels with the remaining ones containing critical information. When two voxels share the same location, we use maxout function to fuse them.
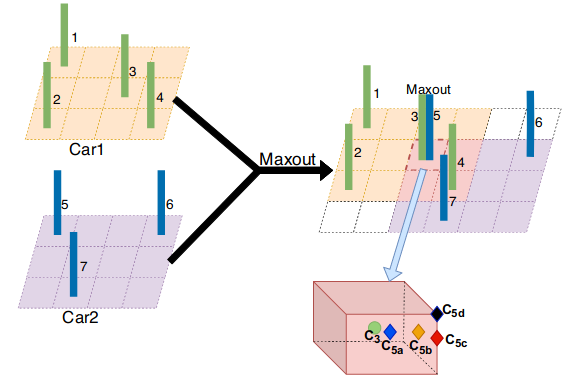
Figure 3. Voxel features fusion.
Spatial Feature Fusion
VFF needs to consider the features of all voxels from two cars, which involves a large amount of data exchanged between vehicles. Fig. 3 intuitively showcases the relationship between VFF and SFF.Different from VFF, we pre-process the voxel features on each vehicle to get the spatial features. Next we fuse the two source spatial features together and forward the fused spatial features to a RPN for region proposal and object detection.
As shown in Figure. 4, the spatial feature maps of a LiDAR frame is generated by the Feature Learning Network. the spatial feature map is a sparse tensor.
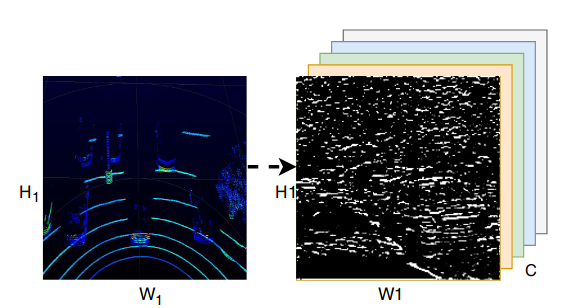
Figure 4. Example of spatial feature maps. H1 and W1 represent the size of the LiDAR bird-eye view for each vehicle’s detection range, while C indicates the channels number.
Similar to VFF adopting the maxout strategy, we also employ maxout for SFF to fuse the overlapped spatial features. Recent work like SENet [13] indicates that different channels share different weights. That is to say some channels in feature maps contribute more toward classification/detection while other channels being redundant or unneeded. Inspired by this, we opt to select partial channels, out of all 128 channels, to transport.
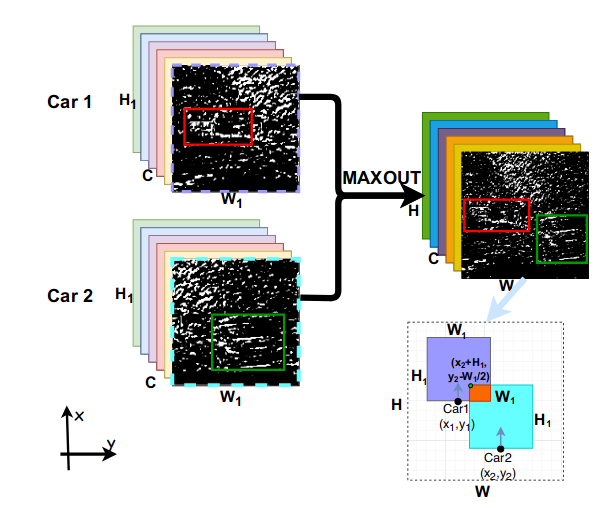
Figure 5. For spatial features fusion, we use maxout to fuse the two spatial features.
Comments
Pros
- Reduce the communication cost.
- Mitigate occlusion problem
Cons
- Have a lower accuracy compared to early-fusion methods, Especially in far scenarios and sparse feature map(SFF)
- SFF sometimes even has a lower accuracy compare to w/o fusion
- Feature fusion relies heavily on location information for fusion, alignment has a big impact on the final detection precision of the fusion.




