
Basic Information
Authors Qi Chen, Sihai Tang, Qing Yang and Song Fu
Organization University of North Texas
Source 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS).
Source Code https://github.com/Aug583/F-COOPER
Content
Motivation
It is easy to determine that some detection failures are caused due to objects being blocked or existing in the blind zones of the sensors. Detection failures could also be caused by bad recognition because the received signal is too weak or because the signal is missing due to system malfunction.
Connected autonomous vehicles (CAV) can share their collected data with each other leading to more information. We propose that information sharing can improve driving performance and experiences.
Dataset
- KITTI, a dataset contains labeled data that allows for autonomous vehicles to train detection models and evaluate detection precision. This paper use the 3D Velodyne point cloud data provided by the KITTI dataset.
- Self-made dataset, two car with necessary sensors, such as LiDARs (Velodyne VLP-16), cameras (Allied Vision Mako G-319C), radars (Delphi ESR 2.5), IMU&GPSes (Xsens MTi-G-710 kit),
Baselines
Cooper and Single shot
Result
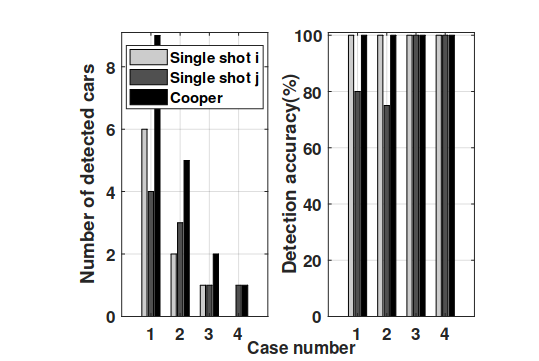
Figure 1. Number of cars detected and the detection scores in four KITTI scenarios.
Method
Since sharing all collected data is also impractical, we need to take into consideration the bandwidth and latency of vehicular networks.
By exchanging LiDAR data, local environment can be reconstructed intuitively by merging point clouds into its physical positions. In order to reconstruct local environment by mapping point clouds into physical positions, additional information is encapsulated into the exchange package. Said package should be constituted from LiDAR sensor installation information and its GPS reading, which determines the center point position of every frame of point clouds.
Sparse Point-cloud Object Detection (SPOD)
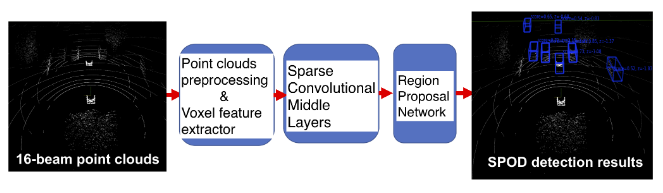
Figure 2. Structure of the SPOD 3D object detection method.
Comments
Pros
- First V2V model
Cons
- Suffer from high communication cost
- fusion methods are too simple, sensitive to noise.
Further work
- data compression.
- Better fusion methods.
Comments
(need further experiment)




