
Basic Information
Authors: Runsheng Xu, Hao Xiang, Xin Xia, Xu Han, Jinlong Li, Jiaqi Ma
Organization: University of California, Los Angeles, Mobility Lab; Cleveland State University, Cleveland Vision and AI Lab,
Source: IEEE International Conference on Robotics and Automation (ICRA)2022
Source Code: https://github.com/DerrickXuNu/OpenCOOD
Content
Motivation
Despite the big potential in Vehicle-to-Vehicle (V2V) communication, it is still in its infancy. One of the major barriers is the lack of a large open-source dataset. Unlike the single vehicle’s perception area where multiple large-scale public datasets exist, most of the current V2V perception algorithms conduct experiments based on their customized data. These datasets are either too small in scale and variance or they are not publicly available. Consequently, there is no large-scale dataset suitable for benchmarking distinct V2V perception algorithms, and such deficiency will preclude further progress in this research field. To address this gap, we present OPV2V, the first largescale Open Dataset for Perception with V2V communication.
We benchmark several state-of-the-art 3D object detection algorithms combined with different multi-vehicle fusion strategies. On top of that, we propose an Attentive Intermediate Fusion pipeline to better capture interactions between connected agents within the network.
Evaluation
Metric: AP@IoU 0.5 0.7
We select a fixed vehicle as the ego vehicle among all spawned CAVs for each scenario in the test and validation set. Detection performance is evaluated near the ego vehicle in a range of x ∈ [−140, 140]m, y ∈ [−40, 40]m.
Datasets
OPV2V datasets, which contains over 70 interesting scenes, 11,464 frames, and 232,913 annotated 3D vehicle bounding boxes, collected from 8 towns in CARLA and a digital town of Culver City, Los Angeles.
Result
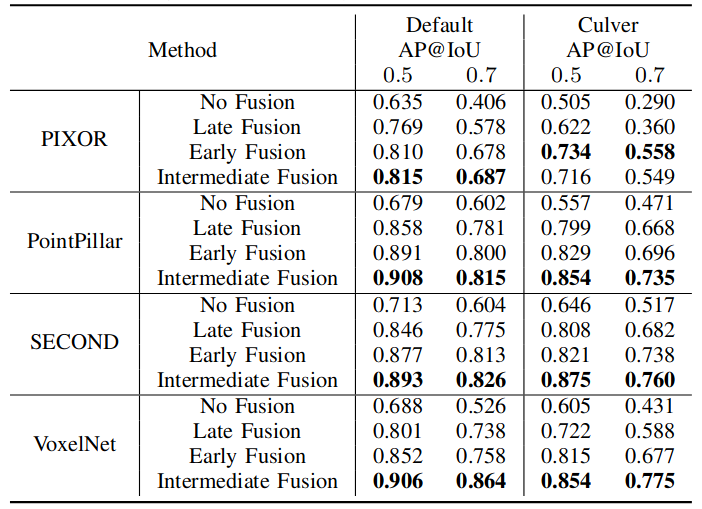
Table 1. Object detection results on default CARLA Towns and digital Culver City.
Method
CARLA is selected as our simulator to collect the dataset, but CARLA itself doesn’t have V2V communication and cooperative driving functionalities by default. Hence, authors employ OpenCDA [18], a co-simulation tool integrated with CARLA and SUMO [25], to generate dataset.
By default, OPV2V supports cooperative 3D object detection, BEV semantic segmentation, tracking, and prediction either employing camera rigs or LiDAR sensors.
Comments
Further work
Hetergenous data
Comments
(need further experiment)




